BirdCLEF 2026: EoS9 Anchor 먼저 — OOF-Gated PCEN 보정은 그 다음
BirdCLEF 2026: EoS9 Anchor 먼저 — OOF-Gated PCEN 보정은 그 다음
대회 링크:
BirdCLEF+ 2026
Kaggle 노트북 링크:
BirdCLEF 2026: EoS9 + OOF-Gated PCEN
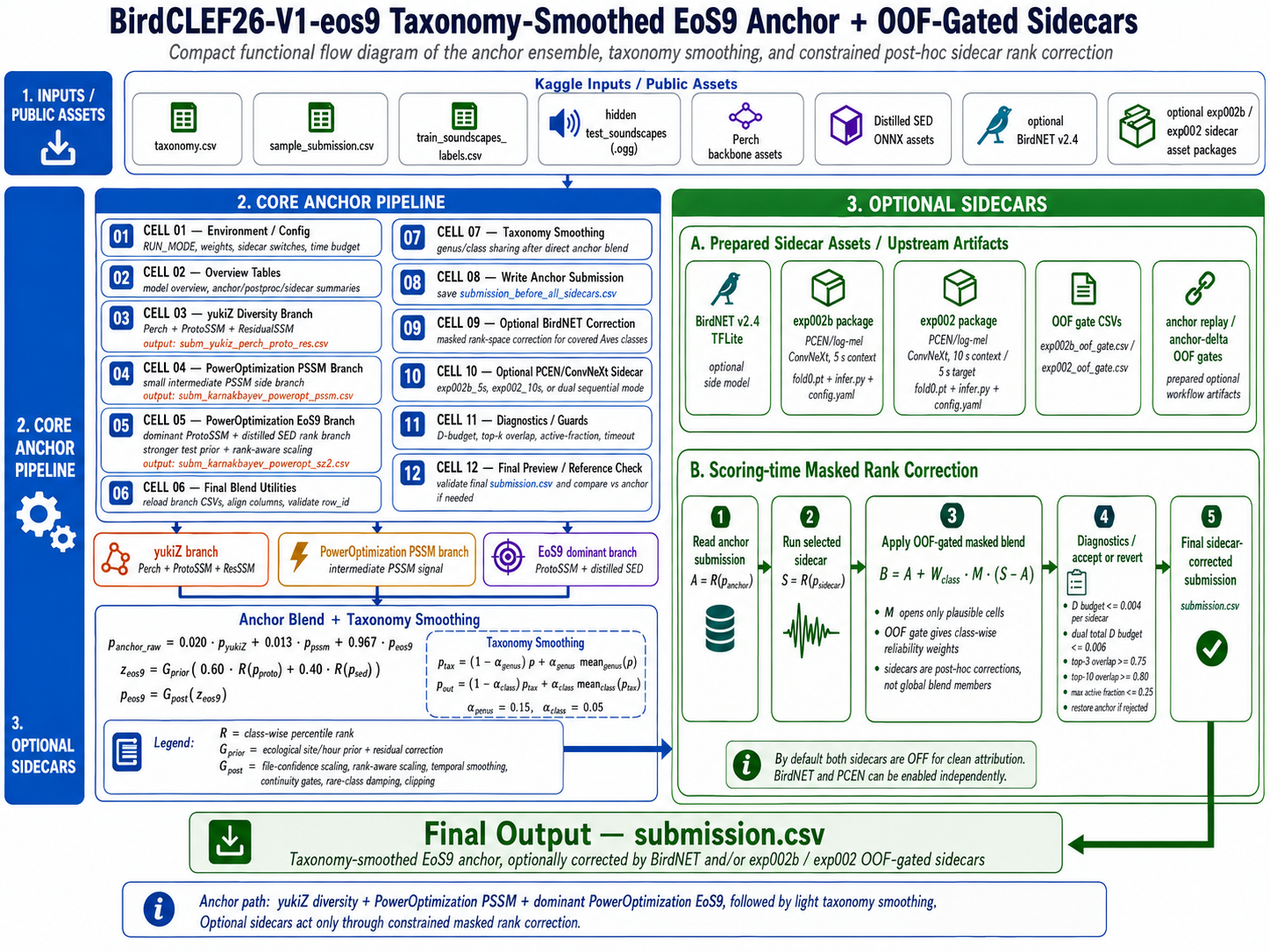
BirdCLEF 2026 제출은 단순히 여러 음향 모델을 평균내는 문제가 아닙니다. row_id 하나는 soundscape의 짧은 시간 구간을 뜻하고, 각 열은 종 또는 분류군 하나를 뜻합니다. 열 수가 많고 라벨 간 상관도 복잡하기 때문에, 작은 확률 변화도 순위에는 의미 있게 작용할 수 있습니다. 반대로 근거가 약한 보조 모델을 전체에 섞으면, 잘 맞던 class까지 함께 망가질 수 있습니다.
그래서 이 구조의 핵심은 보수적입니다.
강한 EoS9 계열 anchor를 먼저 고정하고, 보조 모델은 OOF에서 도움이 된 class와 row에 대해서만 제한적으로 움직이게 한다.
전체 시스템은 세 층으로 나뉩니다.
| 층 | 역할 |
|---|---|
| Anchor | 공개 EoS9 계열 3-branch ensemble로 기본 제출을 만듭니다. |
| Taxonomy smoothing | 가까운 분류군끼리 아주 약하게 정보를 나눕니다. |
| Sidecar correction | BirdNET과 PCEN/ConvNeXt를 보조 correction으로 붙이되, mask, OOF class weight, movement budget을 통과한 곳만 움직입니다. |
활성 설정은 다음과 같습니다.
| 항목 | 값 |
|---|---|
RUN_MODE | eos9_tax |
| Anchor weights | 0.012 yukiZ, 0.021 PowerOptimization PSSM, 0.967 PowerOptimization EoS9 |
| Main rank blend | 0.600 ProtoSSM rank + 0.400 SED rank |
| Taxonomy smoothing | genus 0.15, class 0.05 |
| BirdNET sidecar | enabled, public dry-run에서는 row ID mismatch 시 anchor 유지 |
| PCEN sidecar | enabled, exp002b_5s, fold [0], OOF gate enabled |
| Final dry-run result | 3 rows, 235 columns, finite probabilities in [0.461531, 0.529922] |
전체 원칙은 간단합니다.
1
anchor first, correction second, validation always
1. 제출 파이프라인
기본 anchor는 세 branch의 가중 평균입니다.
\[p_{\text{anchor raw}} = w_y p_{\text{yukiZ}} + w_p p_{\text{PSSM}} + w_s p_{\text{EoS9}}\]가중치는 다음과 같습니다.
\[(w_y, w_p, w_s) = (0.012,\ 0.021,\ 0.967)\]가장 큰 비중은 EoS9 / PowerOptimization 계열 branch에 둡니다. 이 branch 내부에서는 ProtoSSM과 distilled SED 예측을 확률값 그대로 섞지 않고, class별 rank 공간에서 섞습니다.
\[z = 0.60 \cdot R(p_{\text{ProtoSSM}}) + 0.40 \cdot R(p_{\text{SED}})\]여기서 (R(\cdot))는 class별 percentile rank입니다. 확률값 자체가 같은 calibration이라고 보기 어렵기 때문에, raw probability보다 rank를 섞는 편이 더 안정적입니다. 즉, 질문을 이렇게 바꾸는 겁니다.
1
각 branch가 이 row에서 어떤 class를 상대적으로 위에 올려두는가?

direct blend 이후에는 taxonomy smoothing을 적용하고, 먼저 submission.csv를 씁니다. 그 다음에야 선택적으로 sidecar가 rank-space correction을 시도합니다.
1
2
branch CSVs -> direct anchor -> taxonomy smoothing -> submission_before_all_sidecars.csv
-> optional sidecars -> final submission.csv
여기서 sidecar는 새로운 전체 ensemble 멤버가 아닙니다. 이미 만들어진 anchor를 국소적으로 보정하는 후처리 모듈입니다.
2. Anchor가 기준선이 되는 이유
EoS9 anchor는 이미 여러 종류의 강한 구조를 갖고 있습니다. 작은 보조 모델 하나가 한 번에 대체하기 어려운 요소들이 들어 있습니다.
| Anchor 구성 | 역할 |
|---|---|
| yukiZ Perch / ProtoSSM / ResidualSSM | 낮은 비중으로 다양성을 더하는 Perch pretrained path입니다. |
| PowerOptimization PSSM branch | Karnakbayev PowerOptimization pipeline의 중간 branch입니다. |
| PowerOptimization EoS9 branch | ProtoSSM + distilled SED rank branch가 중심인 dominant path입니다. |
| Ecological priors | site/hour와 test prior를 이용해 plausible taxon의 순위를 보정합니다. |
| Temporal smoothing and continuity gates | 단일 window spike를 줄이고 soundscape의 연속성을 반영합니다. |
| Rank-aware scaling | file-level high-confidence class에 추가 구조를 줍니다. |
branch registry를 명시적으로 두는 것도 중요합니다.
| Branch | Weight | Output File | 역할 |
|---|---|---|---|
yukiZ_Perch_ProtoSSM_ResSSM | 0.012 | subm_yukiz_perch_proto_res.csv | 작은 pretrained diversity |
Karnakbayev_PowerOptimization_PSSM | 0.021 | subm_karnakbayev_poweropt_pssm.csv | 중간 PSSM side branch |
Karnakbayev_PowerOptimization_EoS9 | 0.967 | subm_karnakbayev_poweropt_sz2.csv | dominant EoS9 rank branch |
코드: 노트북 상단 control weight
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
RUN_MODE = "eos9_tax"
if RUN_MODE == "eos9_tax":
YUKIZ_BLEND_WEIGHT = 0.012
POWEROPT_PSSM_BLEND_WEIGHT = 0.021
POWEROPT_SZ2_BLEND_WEIGHT = 0.967
elif RUN_MODE == "eos9_no_pssm":
YUKIZ_BLEND_WEIGHT = 0.012
POWEROPT_PSSM_BLEND_WEIGHT = 0.0
POWEROPT_SZ2_BLEND_WEIGHT = 0.988
elif RUN_MODE == "poweropt_eos9_only":
YUKIZ_BLEND_WEIGHT = 0.0
POWEROPT_PSSM_BLEND_WEIGHT = 0.0
POWEROPT_SZ2_BLEND_WEIGHT = 1.0
PROTO_RANK_WEIGHT = 0.600
SED_RANK_WEIGHT = 1.0 - PROTO_RANK_WEIGHT
assert abs(
YUKIZ_BLEND_WEIGHT
+ POWEROPT_PSSM_BLEND_WEIGHT
+ POWEROPT_SZ2_BLEND_WEIGHT
- 1.0
) < 1e-9
assert abs((PROTO_RANK_WEIGHT + SED_RANK_WEIGHT) - 1.0) < 1e-9
이렇게 하면 점수에 영향을 주는 knob이 상단에 드러납니다. 또 가중치 합이 1인지 assert로 확인하기 때문에, 실험을 반복하다가 가중치 조건이 슬그머니 깨지는 일을 막을 수 있습니다.
3. Taxonomy Smoothing
BirdCLEF label은 실제로 서로 독립적이지 않습니다. 같은 genus나 class에 속하거나, 비슷한 habitat와 acoustic confusion을 공유하는 종이 있습니다. Anchor가 이미 강한 class별 순서를 잡았더라도, 가까운 분류군끼리 약간의 정보를 나누는 게 도움이 됩니다.
Genus group (g)에 대해서는 다음 보정을 적용합니다.
\[p_c \leftarrow (1 - \alpha_g)p_c + \alpha_g \operatorname{mean}_{j \in g}(p_j)\]더 넓은 class group (k)에 대해서도 같은 방식으로 약하게 보정합니다.
\[p_c \leftarrow (1 - \alpha_k)p_c + \alpha_k \operatorname{mean}_{j \in k}(p_j)\]활성값은 다음과 같습니다.
\[\alpha_g = 0.15, \qquad \alpha_k = 0.05\]Dry run에서는 taxonomy.csv에서 29개의 multi-species genus group과 4개의 multi-label class group이 만들어졌습니다.

이 단계는 acoustic model을 대체하지 않습니다. 대부분의 anchor score는 그대로 보존하고, 가까운 label에서 아주 조금만 evidence를 빌립니다.
1
2
3
anchor score는 대부분 유지한다.
관련 label끼리 약하게 정보를 나눈다.
최종 schema와 probability range는 다시 검증한다.
코드: taxonomy smoothing
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
def f_TAX_SMOOTHING_POSTPROC(f_direct=direct, genus_alpha=None, class_alpha=None):
submission = f_direct()
genus_alpha = TAX_GENUS_ALPHA if genus_alpha is None else float(genus_alpha)
class_alpha = TAX_CLASS_ALPHA if class_alpha is None else float(class_alpha)
taxonomy_path = _find_taxonomy_path_for_smoothing()
if taxonomy_path is None:
msg = "taxonomy.csv not found; TAX_SMOOTHING cannot be applied"
if globals().get("TAX_SMOOTHING_REQUIRE", True):
raise FileNotFoundError(msg)
submission.index.name = "row_id"
return submission
tax = pd.read_csv(taxonomy_path)
species_to_genus = {}
species_to_class = {}
for _, row in tax.iterrows():
label = str(row.get("primary_label", ""))
sci = str(row.get("scientific_name", ""))
class_name = str(row.get("class_name", ""))
genus = sci.split(" ")[0] if " " in sci else sci
if label:
species_to_genus[label] = genus
species_to_class[label] = class_name
probs = submission.to_numpy(dtype=np.float32, copy=True)
for members in multi_genus.values():
idx = [col_to_idx[m] for m in members]
group_mean = probs[:, idx].mean(axis=1, keepdims=True)
probs[:, idx] = (1.0 - genus_alpha) * probs[:, idx] + genus_alpha * group_mean
for members in multi_class.values():
idx = [col_to_idx[m] for m in members]
group_mean = probs[:, idx].mean(axis=1, keepdims=True)
probs[:, idx] = (1.0 - class_alpha) * probs[:, idx] + class_alpha * group_mean
probs = np.clip(probs, 0.0, 1.0)
return pd.DataFrame(probs, index=submission.index, columns=submission.columns)
4. Sidecar는 새 Anchor가 아니라 국소 보정입니다
활성화된 sidecar는 두 종류입니다.
| Sidecar | 상태 | 사용 목적 |
|---|---|---|
| BirdNET v2.4 | enabled | coverage가 있는 Aves label에 대한 보수적 correction |
| PCEN/ConvNeXt exp002b | enabled | class-wise OOF evidence가 있는 weak-audio correction |
공통 수식은 다음과 같습니다.
\[A = R(p_{\text{anchor}}), \qquad S = R(p_{\text{sidecar}})\] \[B = A + W_{\text{class}} \cdot M \cdot (S - A)\]각 기호의 의미는 다음과 같습니다.
| 기호 | 의미 |
|---|---|
| (A) | taxonomy smoothing 이후 anchor rank |
| (S) | sidecar rank |
| (M) | 움직임을 허용하는 boolean cell mask |
| (W_{\text{class}}) | scalar 또는 class-wise correction weight |
| (B) | 보정된 rank table |
핵심은 sidecar가 anchor를 대체하지 않는다는 점입니다. Sidecar는 anchor가 만든 순위를 조금 움직일 뿐입니다.

Correction은 여러 guard를 통과해야 합니다.
| Guard | 목적 |
|---|---|
| Top-k mask | Anchor나 sidecar가 이미 그럴듯하게 올려둔 class만 움직입니다. |
Anchor threshold tau | Anchor가 낮게 본 class를 sidecar 혼자 끌어올리는 일을 막습니다. |
| OOF class gate | Offline replay에서 anchor에 도움을 준 class만 엽니다. |
Movement budget D | Anchor에서 평균적으로 얼마나 멀리 움직일 수 있는지 제한합니다. |
| Top-3 / top-10 overlap | 예측 상단부가 과하게 뒤집히지 않도록 합니다. |
| Schema validation | row 순서, class column, finite value, [0, 1] 범위를 확인합니다. |
Perturbation budget은 다음과 같습니다.
\[D = \operatorname{mean}\left(\left|B - A\right|\right)\]이번 PCEN sidecar 설정은 다음과 같습니다.
| Knob | Value |
|---|---|
SIDECAR_EXP002_VARIANT | exp002b_5s |
SIDECAR_EXP002_FOLDS | [0] |
SIDECAR_EXP002_WEIGHT_CAP | 0.030 |
SIDECAR_EXP002_D_BUDGET | 0.004 |
SIDECAR_EXP002_ANCHOR_TOPK | 48 |
SIDECAR_EXP002_SIDE_TOPK | 32 |
SIDECAR_EXP002_TAU | 0.55 |
SIDECAR_EXP002_GATE_CSV | exp002b_oof_gate.csv |
SIDECAR_EXP002_USE_OOF_GATE | True |
Gate CSV는 notebook 바깥에서 OOF artifact를 replay하여 만듭니다. Class (c)마다 다음 값을 봅니다.
\[\Delta_c(w) = \operatorname{AUC}_c\left(A + wM(S-A)\right) - \operatorname{AUC}_c(A)\]Masked blend가 shrinkage check 이후에도 안정적으로 양의 개선을 보인 class만 열립니다. 통과하지 못한 class는 gate_weight = 0이므로 anchor 그대로 남습니다.
코드: PCEN OOF gate weight 로딩
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
def _load_exp002_gate_weights(asset_root, class_cols):
if not SIDECAR_EXP002_USE_OOF_GATE:
return None
gate_path = Path(asset_root) / str(SIDECAR_EXP002_GATE_CSV)
if not gate_path.exists():
if SIDECAR_EXP002_GATE_REQUIRE_FILE:
raise FileNotFoundError(f"{SIDECAR_EXP002_LABEL} OOF gate CSV not found")
return None
gate = pd.read_csv(gate_path)
assert "primary_label" in gate.columns
assert "gate_weight" in gate.columns
assert gate["primary_label"].is_unique
weight_map = dict(zip(gate["primary_label"], gate["gate_weight"]))
weights = np.array(
[float(weight_map.get(str(col), 0.0)) for col in class_cols],
dtype=np.float32,
)
weights = np.clip(weights, 0.0, float(SIDECAR_EXP002_GATE_MAX_WEIGHT))
assert np.isfinite(weights).all()
enabled_count = int((weights > 0).sum())
if SIDECAR_EXP002_REQUIRE and enabled_count == 0:
raise ValueError(f"{SIDECAR_EXP002_LABEL} OOF gate has zero enabled classes")
return weights
5. PCEN/ConvNeXt Correction Logic
PCEN sidecar는 custom log-mel / PCEN ConvNeXt path입니다. 활성 variant는 exp002b_5s이고, 주요 설정은 다음과 같습니다.
| Asset Field | Value |
|---|---|
| context seconds | 5.0 |
| target seconds | 5.0 |
| image time | 256 |
| timeout | 600 seconds |
| requested folds | [0] |
PCEN은 anchor branch와 다른 신호를 볼 수 있다는 장점이 있습니다. Anchor는 Perch, ProtoSSM, distilled SED, prior correction, rank scaling에 크게 의존합니다. 반면 PCEN sidecar는 특정 weak audio pattern에서 anchor가 낮게 본 class를 국소적으로 보완할 수 있습니다.
다만 그만큼 위험도 큽니다. 그래서 아래와 같은 단순 전역 blend는 쓰지 않습니다.
1
p_final = 0.97 * p_anchor + 0.03 * p_pcen
대신 masked rank correction으로만 적용합니다.
코드: PCEN masked rank blend
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
def _exp002_masked_rank_blend(anchor_df, side_df, class_weights=None):
assert anchor_df.index.equals(side_df.index)
assert anchor_df.columns.equals(side_df.columns)
A = _exp002_rank_cols(anchor_df).to_numpy(np.float32)
S = _exp002_rank_cols(side_df).to_numpy(np.float32)
mask = _exp002_topk_mask(A, SIDECAR_EXP002_ANCHOR_TOPK) | (
_exp002_topk_mask(S, SIDECAR_EXP002_SIDE_TOPK)
& (A >= float(SIDECAR_EXP002_TAU))
)
if class_weights is None:
E = float(np.mean(mask * np.abs(S - A)))
w_budget = 0.0 if E <= 1e-12 else float(SIDECAR_EXP002_D_BUDGET) / E
w = min(float(SIDECAR_EXP002_WEIGHT_CAP), w_budget)
B = A.copy()
if mask.any() and w > 0:
B[mask] = A[mask] + w * (S[mask] - A[mask])
else:
W = np.clip(class_weights, 0.0, float(SIDECAR_EXP002_GATE_MAX_WEIGHT))
WW = np.broadcast_to(W[None, :], A.shape)
B0 = A.copy()
if mask.any() and W.max() > 0:
B0[mask] = A[mask] + WW[mask] * (S[mask] - A[mask])
D0 = float(np.mean(np.abs(B0 - A)))
if D0 > float(SIDECAR_EXP002_D_BUDGET) and D0 > 1e-12:
W = W * (float(SIDECAR_EXP002_D_BUDGET) / D0)
WW = np.broadcast_to(W[None, :], A.shape)
B = A.copy()
if mask.any() and W.max() > 0:
B[mask] = A[mask] + WW[mask] * (S[mask] - A[mask])
D = float(np.mean(np.abs(B - A)))
top3 = _exp002_topk_overlap(A, B, 3)
top10 = _exp002_topk_overlap(A, B, 10)
ok = (
D > 0.0
and active <= float(SIDECAR_EXP002_MAX_ACTIVE_FRACTION)
and top3 >= float(SIDECAR_EXP002_MIN_TOP3_OVERLAP)
and top10 >= float(SIDECAR_EXP002_MIN_TOP10_OVERLAP)
)
이 코드는 좋은 competition principle 하나를 담고 있습니다.
전문 보조 모델은 class마다 anchor를 움직일 자격을 따로 얻어야 한다.
전역 blend는 sidecar가 전체적으로 calibration되어 있다고 가정합니다. OOF-gated masked rank correction은 더 약하고 현실적인 가정에서 출발합니다. Sidecar는 어떤 class에서는 좋고, 어떤 class에서는 해로울 수 있습니다.
6. BirdNET Sidecar
BirdNET도 같은 방식으로 조심스럽게 다룹니다. 모든 label을 움직이지 않습니다.
| Group | Weight Cap |
|---|---|
| Perch mapping이 있는 covered Aves classes | 0.015 |
| Perch가 약하거나 mapping이 없는 covered Aves classes | 0.060 |
| non-bird classes | 0.000 |
의도는 다음과 같습니다.
1
2
3
BirdNET이 직접 다룰 수 있는 조류 label에서만 사용한다.
Anchor의 직접 mapping이 약한 곳에서는 조금 더 큰 목소리를 준다.
Non-bird taxa는 anchor 그대로 둔다.
Public dry-run에서는 이 branch가 최종 제출을 바꾸지 않았습니다.
1
2
BirdNET row_id mismatch; keeping anchor submission. missing=3, extra=12
BirdNET sidecar elapsed: 2.1s
이 fallback은 의도된 동작입니다. Sidecar가 canonical submission row와 맞지 않으면, 부분적으로 어긋난 correction을 쓰는 대신 anchor를 유지해야 합니다.
7. Public Dry-Run 동작
Public 환경에서 보이는 output은 hidden test soundscape가 mount되지 않은 dry run입니다. 그래서 다음과 같은 일이 생깁니다.
| Stage | Dry-Run Result |
|---|---|
| yukiZ branch | dry-run row에서 실행되고 sample_submission.csv에 align됩니다. |
| PowerOptimization PSSM branch | diagnostic과 intermediate CSV를 씁니다. |
| PowerOptimization EoS9 branch | dominant anchor CSV를 씁니다. |
| taxonomy smoothing | taxonomy.csv를 이용해 정상 적용됩니다. |
| BirdNET sidecar | row ID가 anchor row와 맞지 않아 skip됩니다. |
| PCEN sidecar | test_soundscapes/*.ogg가 보이지 않아 skip됩니다. |
| final output | taxonomy-smoothed anchor 그대로 유지됩니다. |
Notebook output은 다음을 보고합니다.
1
2
3
4
Wrote submission.csv: rows=3, cols=235, min=0.461531, max=0.529922
final_D_vs_base_anchor: 0.0
final_top3_overlap_vs_base: 1.0
final_top10_overlap_vs_base: 1.0
Preview에서 movement가 0이라는 사실은 sidecar가 hidden test에서도 효과가 없다는 뜻이 아닙니다. Public dry run에 sidecar correction을 적용할 실제 soundscape input이 없었다는 뜻입니다. 실제 test run에서는 asset, row ID, class columns, OOF gate, movement diagnostics가 모두 통과할 때만 sidecar path가 실행됩니다.
8. 최종 제출 Writer와 안전 장치
최종 writer는 점수만큼 중요합니다. Kaggle 제출은 모델이 약해서가 아니라 submission.csv의 schema 문제가 슬그머니 섞여 실패하는 경우가 많습니다.
| 실패 유형 | 예시 |
|---|---|
| row mismatch | sidecar가 다른 row_id set을 냅니다. |
| column mismatch | model class order가 sample_submission.csv와 다릅니다. |
| duplicate rows | merge 뒤 row_id가 중복됩니다. |
| invalid values | NaN, inf, [0, 1] 밖의 값이 생깁니다. |
| index leakage | Unnamed: 0 column이 들어갑니다. |
이 구조는 파일을 쓴 뒤 다시 읽어서 확인합니다.
코드: 최종 submission writer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
def _align_to_sample_submission_if_possible(df):
sample_path = _find_sample_submission_path()
if sample_path is None:
return df
sample = pd.read_csv(sample_path)
assert "row_id" in sample.columns
assert sample["row_id"].is_unique
sample_cols = sample.columns.tolist()
missing_cols = [c for c in sample_cols if c not in df.columns]
assert not missing_cols
final_ids = set(df["row_id"])
sample_ids = set(sample["row_id"])
if final_ids == sample_ids:
aligned = (
df.set_index("row_id")
.loc[sample["row_id"], sample_cols[1:]]
.reset_index()
)
aligned.columns = sample_cols
return aligned
raise AssertionError("final row_id set differs from sample_submission")
def write_final_submission(pred, path="submission.csv"):
df = _as_explicit_submission_table(pred)
df = _align_to_sample_submission_if_possible(df)
prob_cols = [c for c in df.columns if c != "row_id"]
values = df[prob_cols].to_numpy(dtype=np.float32)
assert np.isfinite(values).all()
assert values.min() >= 0.0 and values.max() <= 1.0
df.to_csv(path, index=False)
check = pd.read_csv(path)
assert check.columns.tolist() == df.columns.tolist()
assert len(check) == len(df)
assert check["row_id"].is_unique
return df
이건 단순한 방어적 코딩이 아닙니다. Sidecar 실험을 안전하게 만드는 핵심 장치입니다. BirdNET, PCEN, taxonomy smoothing, branch alignment 중 하나라도 schema를 깨면, anchor를 유지하거나 명확히 실패하게 만듭니다.
9. Output을 읽는 법
긴 inference log보다 중요한 건 compact summary입니다.
| Output | 해석 |
|---|---|
| Active model list | 어떤 anchor branch가 실제로 기여하는지 확인합니다. |
| Weight table | outer blend weight 합이 1인지 확인합니다. |
| Sidecar overview | BirdNET과 PCEN이 active인지, 어떤 gate와 budget을 쓰는지 확인합니다. |
| Taxonomy smoothing printout | taxonomy.csv, genus group, class group, alpha 값을 확인합니다. |
| Branch diagnostics | row count, class count, min/max probability, duplicate row를 확인합니다. |
| Final preview | 모든 correction 이후 실제 submission.csv를 보여줍니다. |
| Final delta summary | 최종 rank가 pre-sidecar anchor에서 얼마나 움직였는지 확인합니다. |
Public dry run에서의 핵심 흐름은 다음과 같습니다.
1
Anchor branches run -> taxonomy smoothing applies -> sidecars cannot match dry-run inputs -> final remains anchor.
이 fallback이 정상입니다. Public notebook은 재현 가능하게 유지하고, hidden-test path는 실제 soundscape가 있을 때만 sidecar를 적용할 준비를 합니다.
10. 구조가 주는 장점
가장 중요한 점은 역할 분리입니다.
| 책임 | 구현 방식 |
|---|---|
| 공개 anchor의 강점 유지 | EoS9를 control path로 유지합니다. |
| 생물학적 prior 추가 | direct blend 이후 taxonomy smoothing을 적용합니다. |
| 새 모델의 안전한 사용 | sidecar를 전체 blend가 아니라 masked correction으로 둡니다. |
| rank 과이동 방지 | D budget과 top-k overlap check를 둡니다. |
| offline evidence 사용 | class-wise OOF gate weight를 사용합니다. |
| 제출 형식 보호 | final writer에서 schema와 range를 확인합니다. |
이 구조에서는 실험 결과를 해석하기도 쉽습니다. PCEN sidecar가 좋아지면 anchor 변경 때문이 아니라 sidecar correction 때문입니다. 반대로 나빠지면 active cell이 너무 많았는지, rank movement가 컸는지, OOF gate가 약했는지, row alignment가 깨졌는지를 따로 볼 수 있습니다.
전체 구조를 한 줄로 쓰면 다음과 같습니다.
1
2
3
4
fixed anchor
+ controlled taxonomy prior
+ class gate를 통과한 sidecar correction
+ strict final validation
11. 참고 노트북
| Reference | 여기서의 역할 |
|---|---|
| F.A.Nina, birdclef-2026-eos-9 | primary EoS9 anchor structure |
| Karnakbayev Artur, power-optimization | PowerOptimization branch and validation style |
| yukiZ, Perch + ProtoSSM + ResSSM | low-weight pretrained diversity branch |
| Tucker Arrants, BC2026 Distilled SED | distilled SED ONNX branch |
custom exp002 / exp002b assets | optional PCEN/log-mel ConvNeXt sidecars |
12. 이 구조가 세우는 원칙
BirdCLEF 같은 high-dimensional multilabel audio competition에서는 새 모델을 많이 붙이는 것보다, 새 모델이 움직일 수 있는 범위를 잘 제한하는 편이 더 중요합니다.
이 구조는 다음 원칙을 세웁니다.
- 강한 EoS9 계열 path를 anchor로 둡니다.
- Taxonomy smoothing은 작고 해석 가능한 biological prior로만 사용합니다.
- 보조 모델은 조건 없이 섞는 ensemble member가 아니라 local rank correction으로 씁니다.
- OOF gate를 통해 offline evidence가 있는 class만 움직입니다.
- 최종 writer에서 row, column, finite value, range, duplicate를 끝까지 확인합니다.
결과적으로 PCEN/ConvNeXt와 BirdNET evidence를 붙일 수 있지만, 모든 움직임은 mask, class gate, perturbation budget을 통과해야 합니다.
마지막 요지는 이렇습니다.
큰 multilabel audio table에서 새 모델을 가장 안전하게 쓰는 방법은 모든 곳에 섞는 것이 아닙니다. 충분한 근거가 있는 곳에서만 움직이게 하는 것입니다.