ROGII: Target-Free 지층 대비로 TVT 복원하기 — 데이터 누수 통제 설계
ROGII: Target-Free 지층 대비로 TVT 복원하기 — 데이터 누수 통제 설계
Competition link:
ROGII Wellbore Geology Prediction
Kaggle code:
ROGII EDA: Target-Free Alignment for TVT
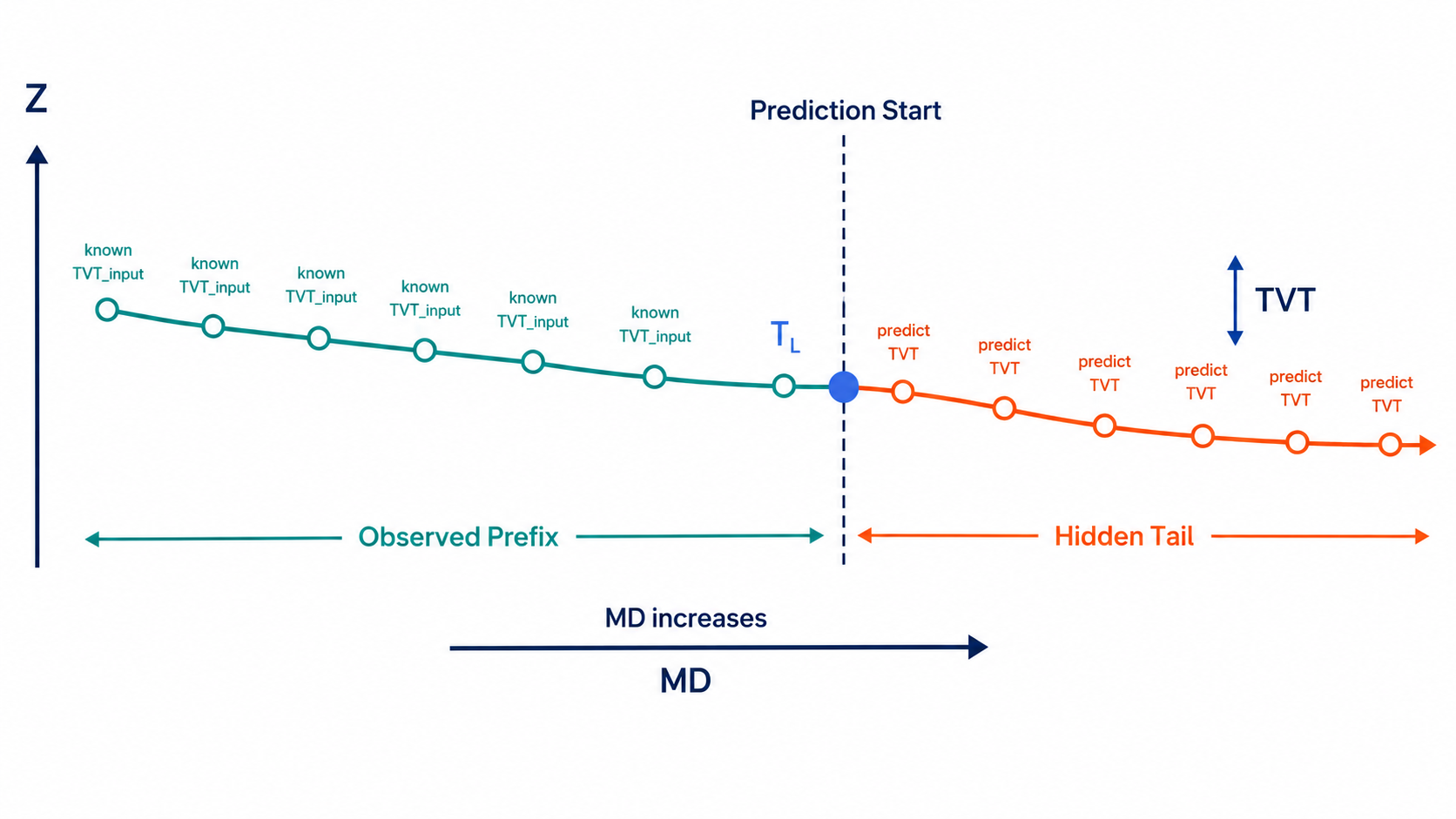
이 문제에서 예측해야 하는 값은 수평정(horizontal well)의 숨겨진 후반 구간에 있는 TVT, 즉 true vertical thickness입니다. 각 테스트 시추공은 앞부분 일부 구간에 대해서만 TVT_input이 주어집니다. 그 뒤로 길게 이어지는 구간의 TVT는 MD, X/Y/Z, GR 같은 관측값만 가지고 복원해야 합니다.
겉으로 보면 한 컬럼을 맞히는 회귀 문제처럼 보이지만, 실제로는 조금 다릅니다. 각 행은 독립적인 표본이 아니라 시추공을 따라 지나가는 하나의 지점입니다. MD는 드릴이 실제로 지나간 경로 길이이고, X/Y/Z는 그 지점의 공간 좌표입니다. 수평정은 옆으로는 수천 피트씩 이동해도 수직 위치는 상대적으로 천천히 변할 수 있습니다. 그래서 TVT는 단순히 “얼마나 깊은가”가 아니라, 시추공이 지층 안에서 어느 위치를 지나고 있는지를 나타내는 좌표에 가깝습니다.
먼저 용어를 간단히 정리해 보겠습니다.
| 용어 | 의미 |
|---|---|
MD | measured depth입니다. 시추공을 따라 잰 거리라서 계속 증가합니다. |
X/Y/Z | 시추공의 공간 좌표입니다. 이 중 Z가 수직 위치를 담고 있습니다. |
TVD | true vertical depth입니다. 경로 길이가 아니라 수직 방향 깊이입니다. |
TVT | true vertical thickness입니다. 지층 안에서의 상대적 위치를 표현하는 좌표로 볼 수 있습니다. |
GR | gamma-ray log입니다. 암상과 셰일 함량 변화에 반응하는 경우가 많습니다. |
| Typewell | TVT -> GR 관계를 알고 있는 기준 수직정입니다. |
| Horizontal well | 앞부분 TVT만 알려져 있고 후반 구간 TVT를 복원해야 하는 대상 수평정입니다. |
문제의 구조를 정리하면 이렇습니다.
1
2
3
4
5
6
7
8
typewell:
TVT -> GR reference curve
horizontal well:
MD/X/Y/Z -> GR observed curve
goal:
MD/X/Y/Z/GR -> TVT hidden curve
한 행씩 따로 예측하는 문제라기보다는, 알려진 앞부분에서 시작해 숨겨진 후반 구간의 TVT 곡선을 이어 붙이는 문제입니다. 이 곡선은 시추공의 궤적, GR 패턴, 기준 typewell, 주변 지층 구조를 모두 함께 봐야 합니다.
핵심 과제는 데이터 누수를 막는 것입니다. 사용할 수 있는 정보와 절대 보면 안 되는 정보가 분명히 나뉩니다.
1
2
3
4
5
6
7
8
Known at prediction time:
MD, X, Y, Z, GR, prefix TVT_input
Hidden:
tail TVT
Useful but dangerous:
same-well train/test overlap, formation tops, full-tail covariate paths, OOF artifacts
이 문제의 핵심 원칙은 딱 하나입니다.
1
2
Use every target-free geological signal,
but never let hidden-tail TVT leak into validation or inference.
여기서 target-free는 “아무 정보도 쓰지 않는다”는 뜻이 아닙니다. 정답값인 숨겨진 TVT를 직접 보지 않는다는 뜻입니다. 전체 시추 궤적, GR 곡선, typewell 곡선, 알려진 앞부분의 TVT, fold 안에서 안전하게 만든 지층 구조 추정치는 사용할 수 있습니다. 다만 숨겨진 후반 구간의 TVT label이나, 그 label에서 파생된 통계량은 검증과 추론에 들어가면 안 됩니다.
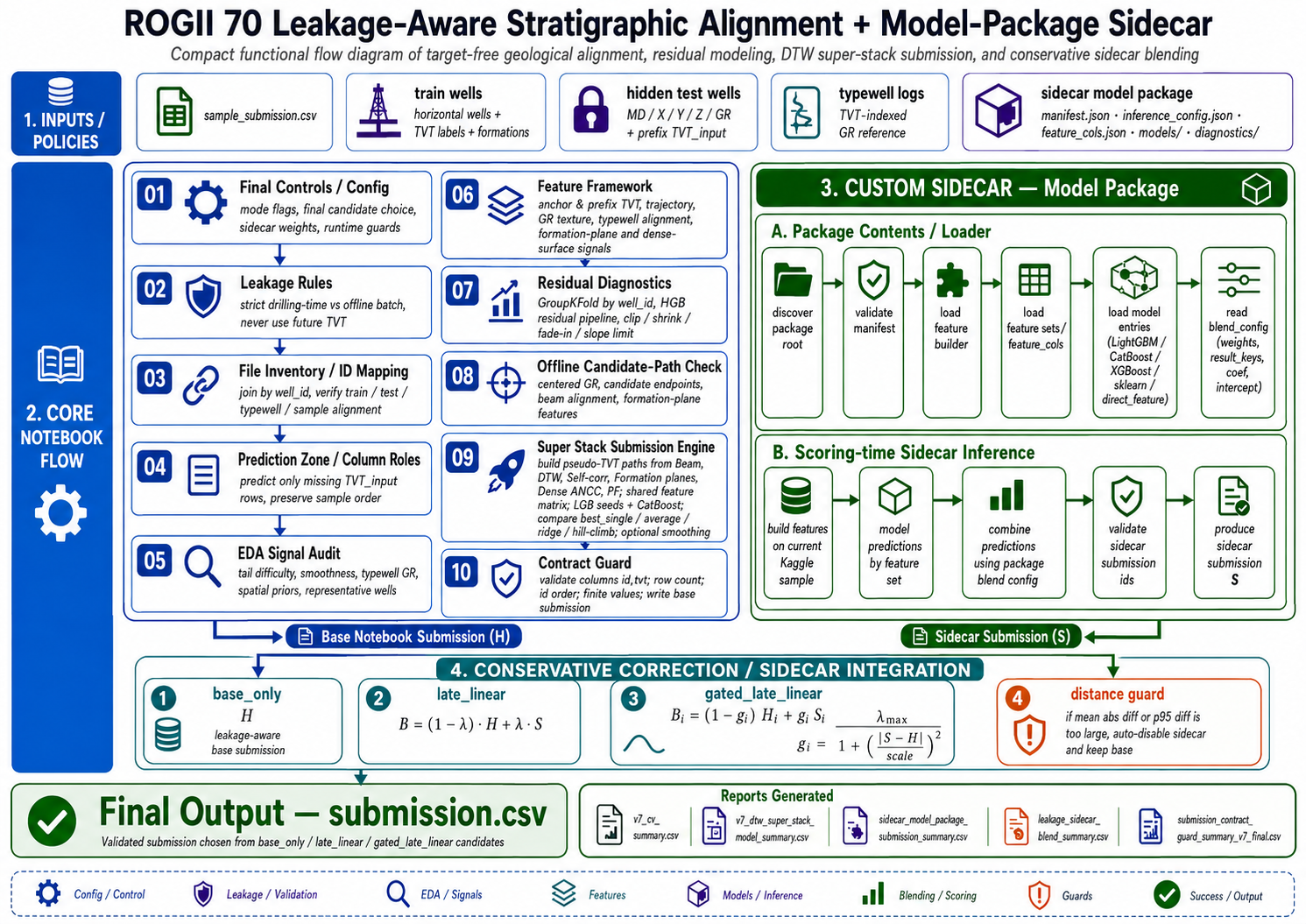
전체 흐름은 다음과 같습니다.
| 단계 | 역할 |
|---|---|
| 앞부분 anchor | 마지막으로 알려진 TVT_input을 출발점으로 둡니다. |
| 궤적 정보 | MD, X/Y/Z의 움직임으로 경사, 곡률, 수직 변화량을 봅니다. |
| GR 바코드 | horizontal GR 곡선을 typewell GR 곡선과 대비합니다. |
| 지층 구조 | TVT + Z가 공간적으로 얼마나 안정적인지 확인합니다. |
| PF / beam / DTW | 정답값을 보지 않고 가능한 TVT 경로를 여러 방식으로 만듭니다. |
| 잔차 모델 | 물리적 경로가 언제 얼마나 빗나가는지 보정합니다. |
| 제출 검증 | id,tvt 형식과 sample order를 끝까지 지킵니다. |
의존 방향도 이 순서를 지키는 게 안전합니다.
1
2
3
4
5
observed covariates
-> target-free geological hypotheses
-> reliability features
-> residual correction
-> conservative post-processing
먼저 지질적으로 말이 되는 후보 경로를 만들고, 그 다음에 모델이 그 경로의 편향을 고치는 구조입니다. 이렇게 해야 모델이 행 번호나 우연한 패턴만 보고 임의의 TVT 곡선을 만들어내는 일을 줄일 수 있습니다.
guarded pf_residual_gbdt 설정의 결과 요약은 다음과 같습니다.
| Quantity | Value |
|---|---|
| Train horizontal wells | 773 |
| Test horizontal wells | 3 |
| Submission rows | 14,151 |
| Train hidden-tail rows | 3,783,989 |
| PF-only OOF RMSE | 11.0106 |
| PF + residual GBDT OOF RMSE | 10.5696 |
| Final prediction mean | 11906 |
| Final prediction std | 277.81 |
| Final prediction range | 11601 to 12242 |
RMSE 개선폭만 보면 아주 커 보이지 않을 수 있습니다. 하지만 기준이 단순 평균이나 tabular baseline이 아니라 이미 물리적으로 제약된 PF 경로라는 점을 생각하면, 이 정도의 잔차 개선도 충분히 의미가 있습니다.
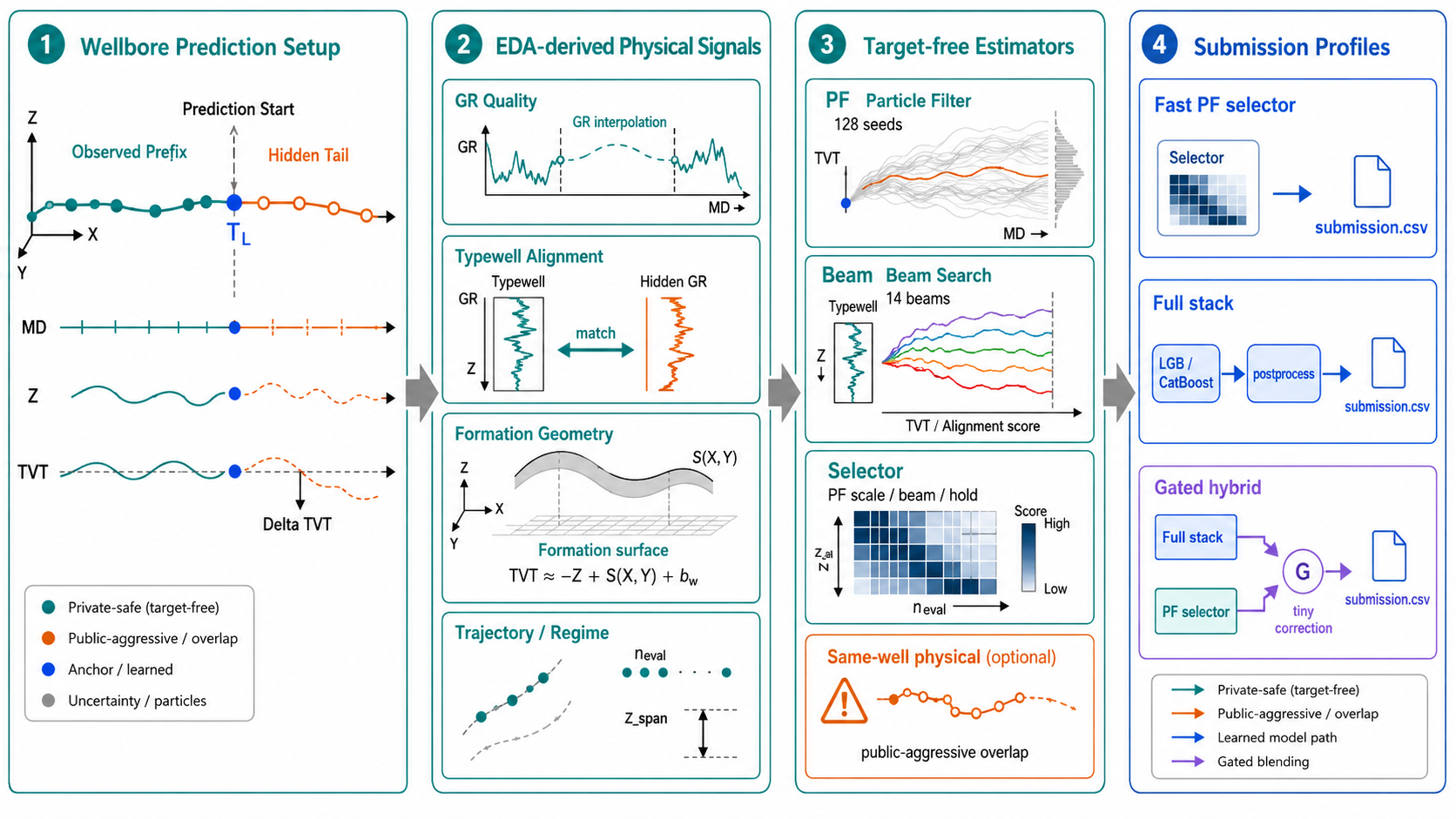
1. 숨겨진 후반 구간의 구조
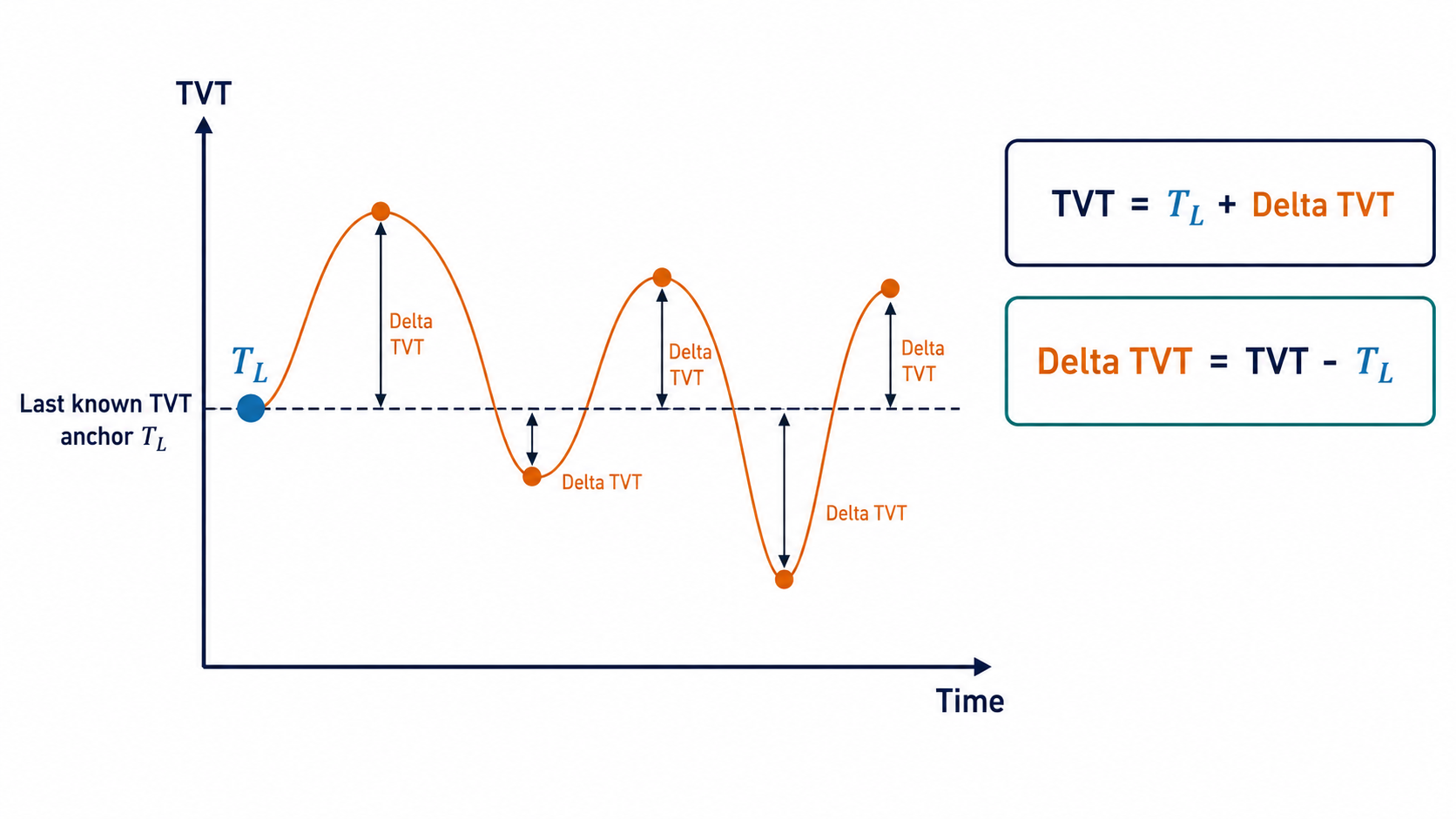
각 시추공은 알려진 앞부분과 숨겨진 후반 구간으로 나뉩니다. 알려진 앞부분의 마지막 TVT는 자연스러운 기준점이 됩니다.
\[T_{w,L} = \operatorname{last\_known\_TVT}(w)\]따라서 TVT 자체를 바로 맞히기보다, 이 기준점에서 얼마나 벗어나는지를 예측하는 편이 더 안정적입니다.
\[\Delta T_{i} = T_i - T_{w,L}\]최종 예측은 다음처럼 쓸 수 있습니다.
\[\hat{T}_{i} = T_{w,L} + \widehat{\Delta T}_{i}\]후반 구간은 보통 마지막으로 알려진 TVT 근처에서 시작합니다. 예측 시작 직후부터 anchor에서 멀리 벗어나면, 실제 지질 신호가 충분히 쌓이기 전에 많은 행에서 손해를 볼 수 있습니다.
알려진 앞부분은 단순한 시작값이 아닙니다. 시추공마다의 local coordinate system을 잡아주는 역할을 합니다.
| 앞부분에서 얻는 정보 | 의미 |
|---|---|
마지막 TVT_input | 예측 시작점의 지층 위치입니다. |
| 앞부분 GR과 typewell GR의 차이 | 이 시추공의 GR 보정 상태를 보여줍니다. |
| 앞부분 TVT slope | 후반 구간으로 들어가기 직전의 TVT 변화 방향입니다. |
| 앞부분 궤적 slope와 curvature | 시추공이 어떤 방향으로 움직이고 있었는지를 보여줍니다. |
| formation surface 대비 잔차 | 시추공 고유의 local offset을 추정하게 해줍니다. |
그래서 예측은 전체 평균이나 행 번호에서 출발하지 않습니다. 이미 알려진 지질 상태에서 출발하고, 각 후보 경로가 그 상태에서 얼마나 자연스럽게 이어지는지를 봅니다.
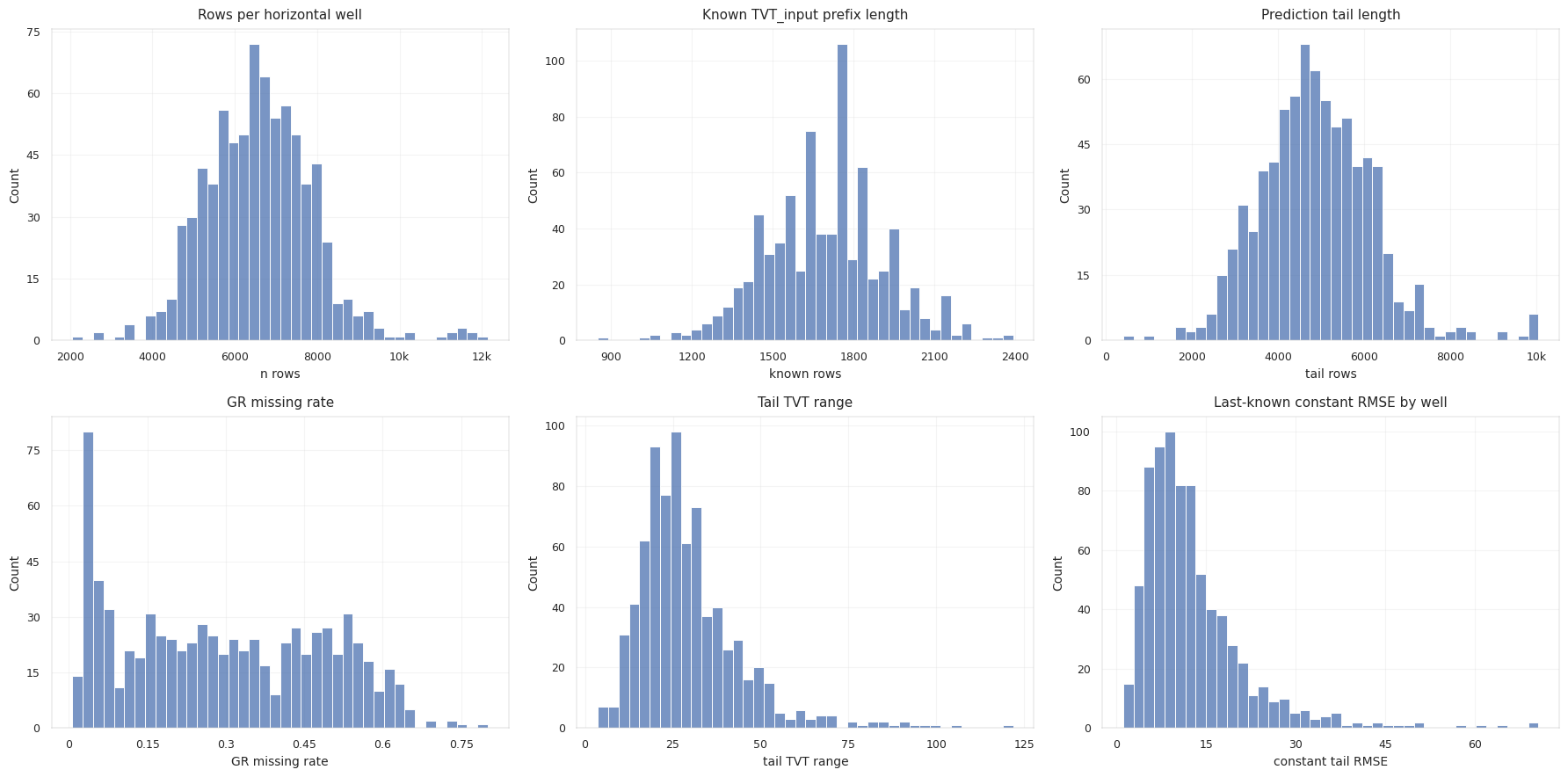
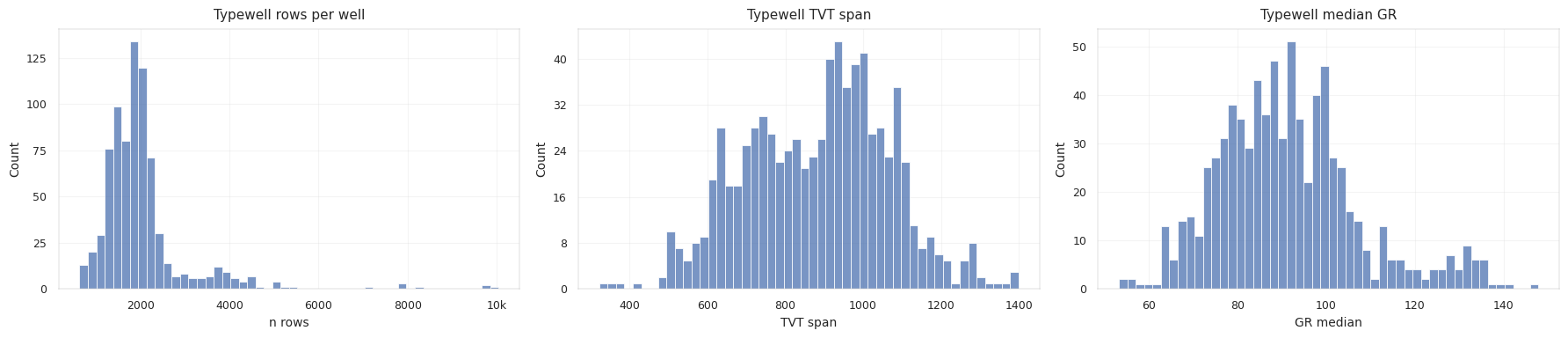
학습용 시추공을 요약하면, 대부분 앞부분 뒤에 하나의 긴 숨겨진 구간이 붙어 있습니다.
| Tail Statistic | Mean | Median | 95% | Max |
|---|---|---|---|---|
known_rows | 1692.5 | 1703 | 2053 | 2392 |
tail_rows | 4895.2 | 4840 | 6918 | 10052 |
tail_tvt_range | 29.41 | 26.37 | 54.42 | 121.84 |
constant_tail_rmse | 12.81 | 10.67 | 29.01 | 70.64 |
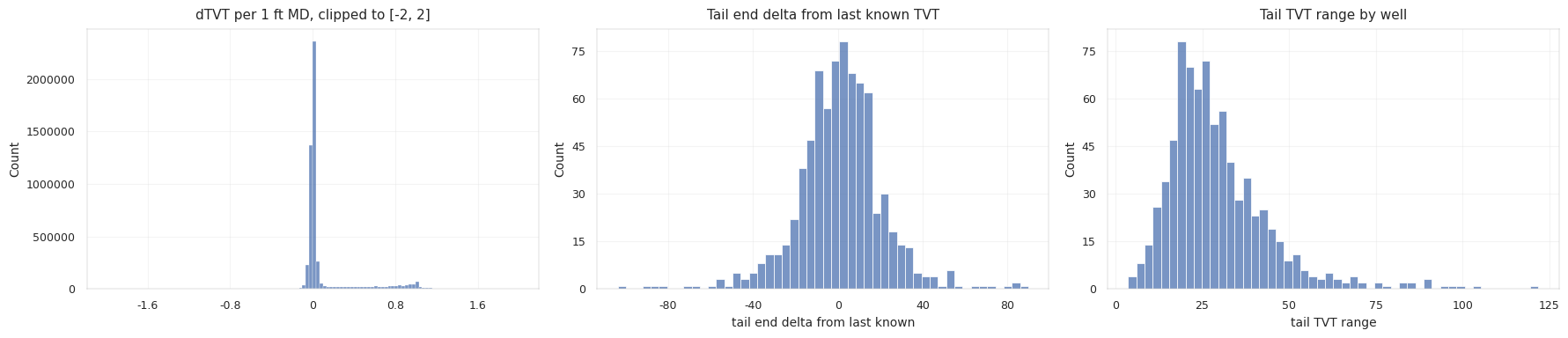
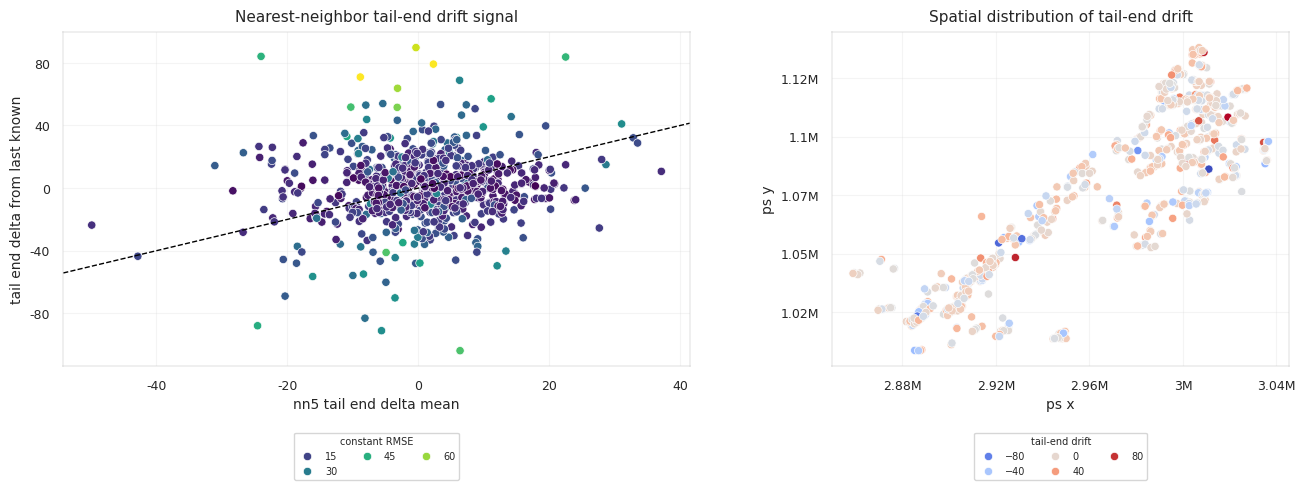
마지막으로 알려진 anchor는 꽤 강력한 기준점입니다. 수평정은 대개 목표 지층 안에 머무르도록 뚫기 때문에, 실제 TVT가 거의 움직이지 않는 경우도 많습니다. 하지만 모든 시추공이 그렇지는 않습니다. 시추공이 위아래로 움직이거나, 지층 경계 근처를 지나거나, 기울어진 지층을 따라가면 TVT는 수천 행에 걸쳐 천천히 변할 수 있습니다.
결국 좋은 예측이 갖춰야 할 조건은 두 가지입니다. 평평한 시추공에서는 괜히 움직이지 않고, 실제로 drift하는 시추공은 따라갈 수 있어야 합니다.
1
2
3
5,000개 행에 걸쳐 5피트 bias가 계속 유지된다면
그것은 국소적인 오차가 아닙니다.
후반 구간 전체를 잘못된 지층 위치에 놓은 것입니다.
후반 구간이 길기 때문에 작은 bias도 누적됩니다. 그래서 이 문제는 독립 행 예측이라기보다 경로 예측에 가깝습니다. smoothing, slope clipping, fade-in은 단순한 후처리가 아니라 TVT 곡선의 물리적 형태를 반영하는 장치입니다.
2. 데이터 누수의 경계
정보 경계는 크게 두 가지 관점으로 나눌 수 있습니다.
| 모드 | 허용되는 정보 | 금지되는 정보 |
|---|---|---|
| Strict drilling-time | 앞부분 TVT_input, 현재 행의 geometry, trailing window, 앞부분 기반 GR 보정 | 미래 행, centered window, tail length, tail TVT |
| Offline batch | test에 제공된 전체 MD/X/Y/Z/GR, 후보 경로, tail geometry | tail TVT, target-derived summary, test에서 직접 관측할 수 없는 train-only formation top |
offline mode가 곧바로 데이터 누수라는 뜻은 아닙니다. Kaggle test 파일에는 전체 시추 궤적과 전체 GR sequence가 이미 들어 있습니다. 따라서 미래 행의 GR이나 X/Y/Z를 쓰는 것은 가능합니다. 문제는 그 정보가 숨겨진 TVT label을 거쳐 만들어진 값이면 안 된다는 점입니다.
1
2
Future covariates are allowed only if they are available in the test file
and are not transformed through hidden target values.
이 구분이 중요합니다.
첫째, 후반 구간의 covariate를 전부 버릴 필요는 없습니다. full horizontal GR trace를 이용해 typewell GR과 DTW를 수행하는 것은 target-free입니다. 관측된 GR끼리 맞추는 것이지, 숨겨진 TVT label을 보는 것이 아니기 때문입니다.
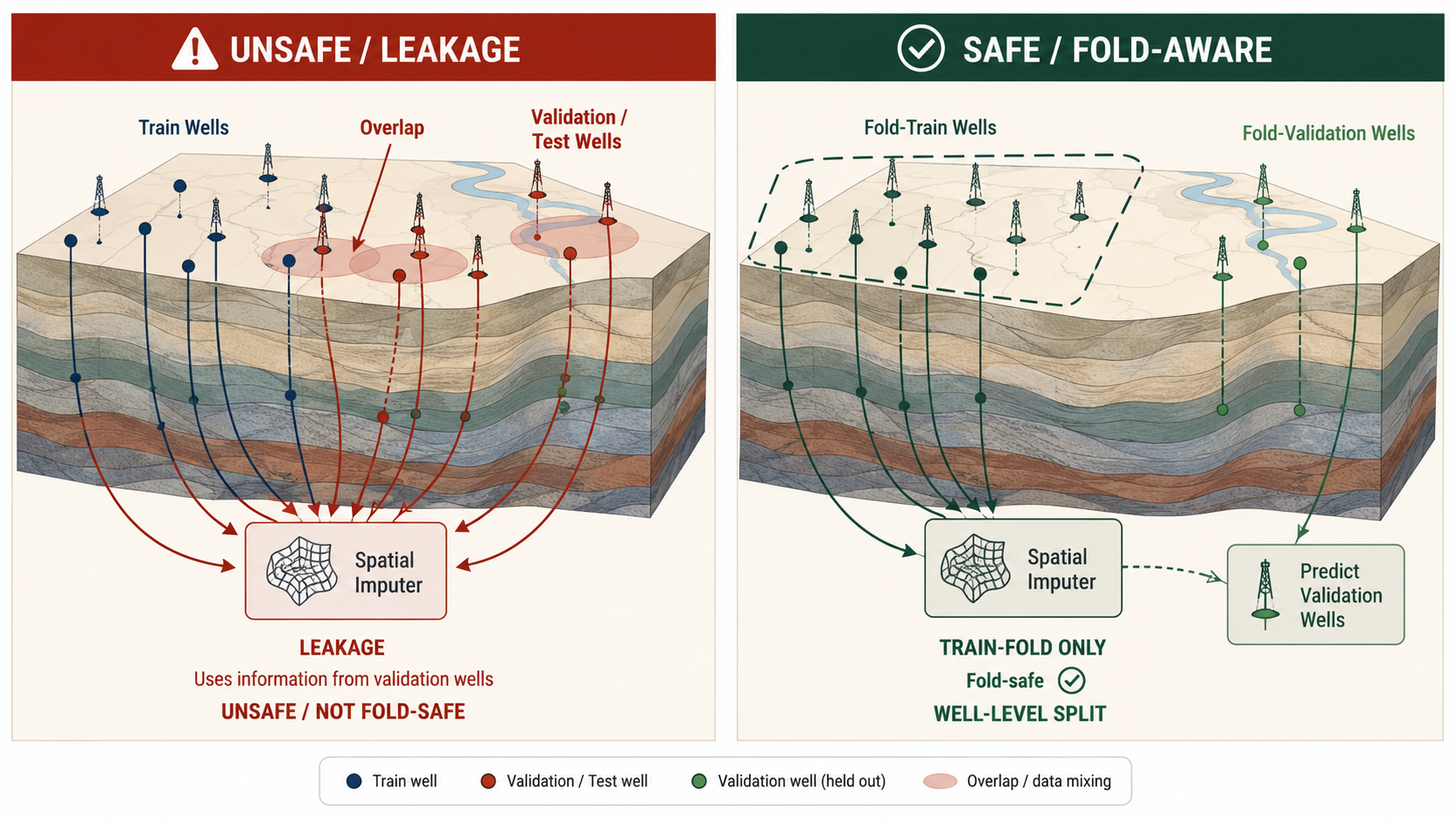
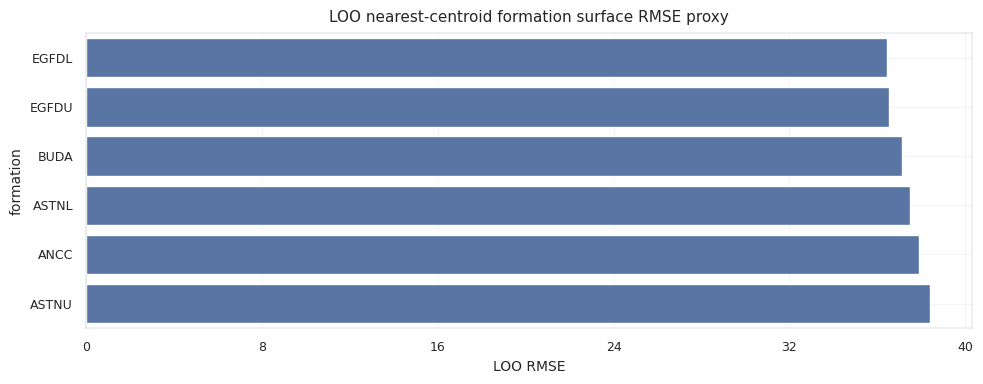
둘째, train에 있는 지질 컬럼을 무조건 안전하다고 보면 안 됩니다. ANCC, ASTNU, ASTNL, EGFDU, EGFDL, BUDA 같은 formation top은 train에서는 강력한 설명 변수지만 test horizontal file에는 직접 존재하지 않습니다. validation fold에서 held-out well의 true formation top을 그대로 쓰면, 실제 추론 때 사용할 수 없는 정보를 보고 검증하는 셈입니다.
안전한 방식은 fold 안에서만 surface를 학습하고, held-out well에는 그 추정 surface를 투영하는 것입니다.
1
2
3
4
5
6
7
8
9
10
for train_idx, valid_idx in GroupKFold(n_splits=5).split(wells, groups=well_id):
train_wells = wells.iloc[train_idx]
valid_wells = wells.iloc[valid_idx]
surface = fit_formation_surface(train_wells)
valid_features = build_features(
valid_wells,
formation_source=surface,
target_columns=None,
)
검증 흐름도 최종 추론과 같은 모양이어야 합니다.
1
2
3
4
fit on training-fold wells
build target-free features for held-out wells
predict held-out hidden tails
score only hidden-tail TVT
held-out well에 자기 자신의 true tail label, true formation top, target-derived summary를 넘겨주는 순간, 검증은 일반화 평가가 아니라 암기 테스트가 됩니다.
주의해야 할 패턴은 다음과 같습니다.
| 패턴 | 위험 | 안전한 처리 |
|---|---|---|
| Row random split | 같은 시추공 안의 autocorrelation이 검증으로 새어 들어갑니다 | well_id 기준 GroupKFold를 사용합니다. |
| Formation tops in horizontal train file | test에 없는 직접적인 지질 대리 변수입니다 | fold 안에서 학습한 spatial imputation으로 재구성합니다. |
TVT_input backfill | tail target을 뒤에서 앞으로 복사하게 됩니다 | 앞부분만 사용합니다. |
| Tail TVT summaries | 직접적인 target leakage입니다 | 완전히 제외합니다. |
| Nearby validation well labels | fold 사이 공간 leakage가 생깁니다 | training-fold well만으로 spatial/formation estimator를 fit합니다. |
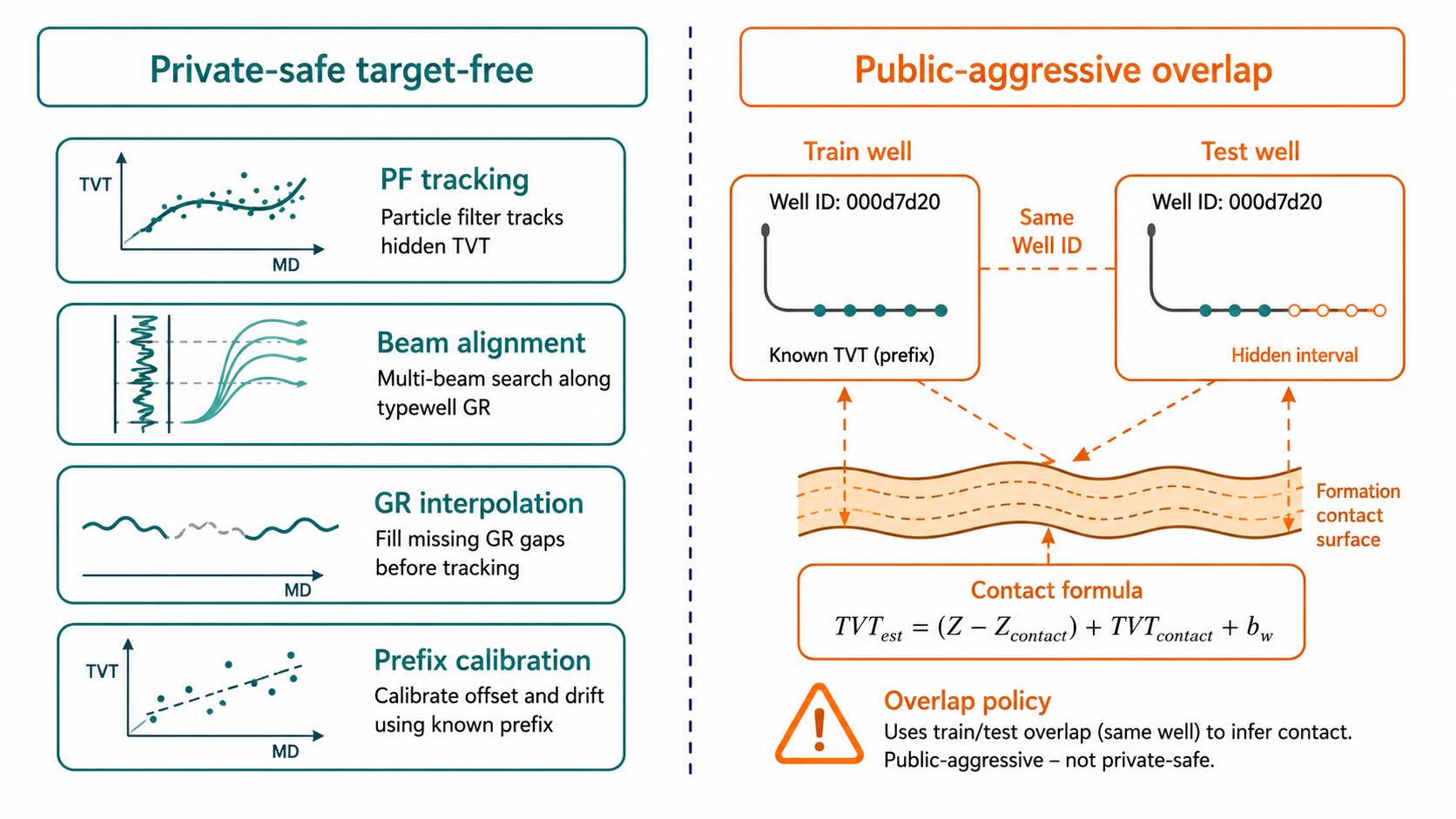
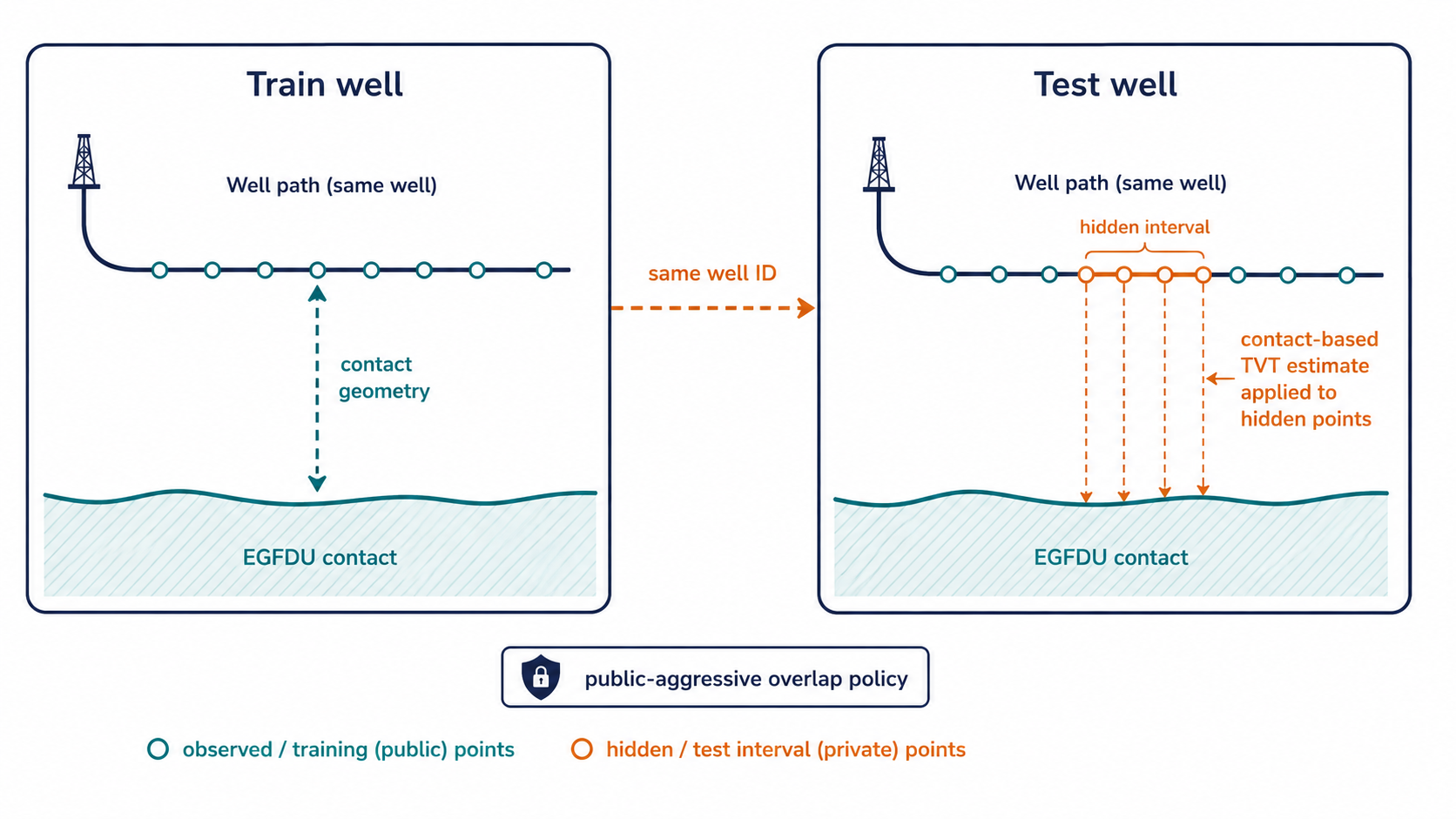
| Same-well train/test overlap | public well이 train ID를 반복하면 public LB를 지배할 수 있습니다 | 겹침을 쓰는 모드와 끄는 모드를 분리해 비교합니다. |
같은 well의 물리적 궤적을 이용하는 방식이 곧바로 정답 유출을 뜻하지는 않습니다. test 파일에서 볼 수 있는 geometry와 앞부분 정보만 사용한다면 규칙 안에 있는 추정입니다. 다만 공개 점수와 비공개 점수 사이의 위험이 달라집니다. public test의 well은 train well과 겹치지만 private well은 겹치지 않는다면, 공개 점수는 일반화 능력이 아니라 우연한 겹침을 보상할 수 있습니다.
그래서 질문을 둘로 나누어야 합니다.
| 질문 | 진단 |
|---|---|
| test-file 정보 경계 안에서 합법적인가? | test에 제공된 covariate와 앞부분 정보만 쓰는가? |
| private split shift에도 견고한가? | 같은 well 겹침을 끄고도 작동하는가? |
공개 점수에 맞춘 겹침 활용 경로는 규칙상 허용될 수 있지만, 같은 겹침이 private에서 사라지면 쉽게 무너질 수 있습니다. 반대로 비공개 일반화용 경로는 public overlap에 덜 특화되지만, 처음 보는 시추공에서 얼마나 버티는지를 더 잘 보여줍니다. 두 경로를 분리해 보아야 점수의 의미를 해석할 수 있습니다.
스위치는 명시적으로 둡니다.
1
2
3
4
5
6
7
SUBMISSION_PROFILE = "pf_residual_gbdt"
# Public-aggressive overlap policy:
PF_SELECTOR_USE_SAME_WELL_PHYSICAL = True
# Private-safe robustness probe:
PF_SELECTOR_USE_SAME_WELL_PHYSICAL = False
selector의 선택 규칙은 다음과 같습니다.
\[\hat{T}^{selector}_i = \begin{cases} \hat{T}^{same\ well}_i, & \text{if same-well mode is enabled and a matching well is available} \\ \operatorname{Select}(H^{PF}, H^{beam}, H^{hold}\mid X,Y,Z,GR,T_{prefix}), & \text{otherwise} \end{cases}\]같은 well의 겹침 정보를 쓰는 경로는 일반적인 PF/beam selector와 성격이 다릅니다. 하나는 특정 overlap 구조를 이용하는 기하학적 지름길에 가깝고, 다른 하나는 보편적인 지층 추적기입니다. 이 둘을 명시적으로 나누어야 공개 점수가 무엇을 반영했는지 추적할 수 있습니다.
1
2
3
4
5
same-well on:
공개 test와 train의 겹침을 활용하는 가설
same-well off:
처음 보는 well에도 적용되는 지층 추적 가설
3. 감마선 로그를 지층의 바코드로 보기
Gamma ray는 단순한 숫자 컬럼이 아닙니다. horizontal well과 typewell을 이어주는 핵심 관측 신호입니다. Gamma log는 borehole 주변의 자연 방사능을 측정합니다. 많은 퇴적 환경에서 shale-rich interval과 깨끗한 sand 또는 carbonate interval은 서로 다른 gamma response를 보입니다. 그래서 GR 곡선은 지층의 반복 가능한 패턴, 일종의 바코드처럼 작동할 수 있습니다.
typewell은 기준 곡선을 줍니다.
1
TVT -> GR
horizontal well은 관측된 sequence를 줍니다.
1
MD -> GR
우리가 복원해야 하는 건 바로 이 mapping입니다.
1
MD -> TVT
즉 horizontal GR 곡선을 typewell GR 곡선과 대비하여, MD 좌표 위에 놓인 관측값을 TVT 좌표로 옮겨야 합니다.
이 대비는 단순 lookup이 아닙니다. 수평정은 같은 층 안에 머무를 수도 있고, 천천히 다른 층으로 넘어갈 수도 있습니다. 국소적인 dip, fault, thickness change가 있을 수도 있습니다. 따라서 horizontal GR 곡선은 typewell의 어떤 구간이 늘어나거나 줄어들거나, 이동하거나, 일부 결측된 형태로 나타날 수 있습니다.
서로 다른 변형 패턴을 다루기 위해 여러 방법을 함께 씁니다.
| 방법 | 잘 맞는 경우 | 약한 경우 |
|---|---|---|
| Direct prefix calibration | 예측 시작점 근처의 작은 local offset | 후반 구간이 앞부분 behavior에서 멀리 drift할 때 |
| DTW | GR pattern의 stretching/squeezing | GR 결측이나 반복 motif가 match를 애매하게 만들 때 |
| Beam path | 여러 local path hypothesis를 유지해야 할 때 | search grid가 true path를 놓칠 때 |
| PF | 불확실성을 순차적으로 들고 가야 할 때 | likelihood가 길게 약하거나 noisy할 때 |
| Formation estimate | 공간적으로 일관된 dipping surface가 있을 때 | 시추공별 local offset이 지배적일 때 |
GR 곡선만으로 TVT가 하나로 결정되지는 않습니다. 다만 가능한 TVT path의 범위를 좁혀줍니다. 최종 path는 geometry, 앞부분 calibration, formation position, smoothness와 얼마나 일관적인지를 종합해서 결정합니다.
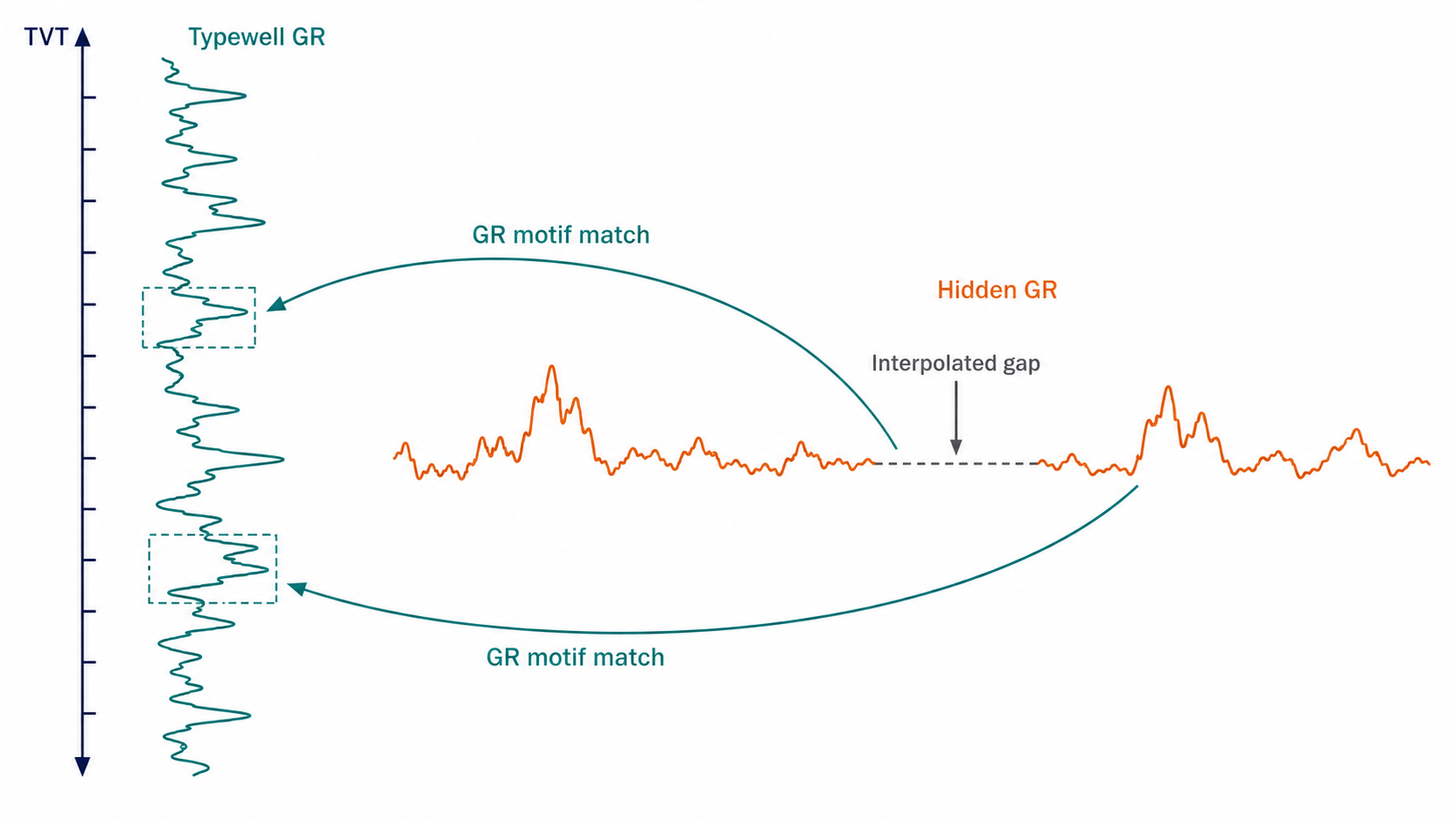
앞부분에는 TVT_input이 있으므로 GR 대비의 품질을 실제로 측정할 수 있습니다. 알려진 TVT 위치에서 horizontal GR과 typewell GR을 비교합니다.
앞부분 잔차의 스케일은 다음과 같이 정의합니다.
\[\sigma_{GR,w} = \operatorname{std}(r_i)\]이 값은 시추공별 관측 noise 추정치가 됩니다. 앞부분 correlation이 약하거나 residual scale이 크면 typewell matching을 덜 믿어야 합니다.
또한 GR 값의 scale이나 baseline이 시추공마다 조금씩 다를 수 있습니다. 이때 known prefix만으로 affine calibration을 fit할 수 있습니다.
\[GR^{calibrated}_i = a_w GR_i + c_w\]이 calibration은 알려진 앞부분에서만 학습하고, 숨겨진 후반 구간에는 그대로 적용합니다. 후반 구간 TVT label로 a_w, c_w를 조정하면 그때부터는 데이터 누수입니다.
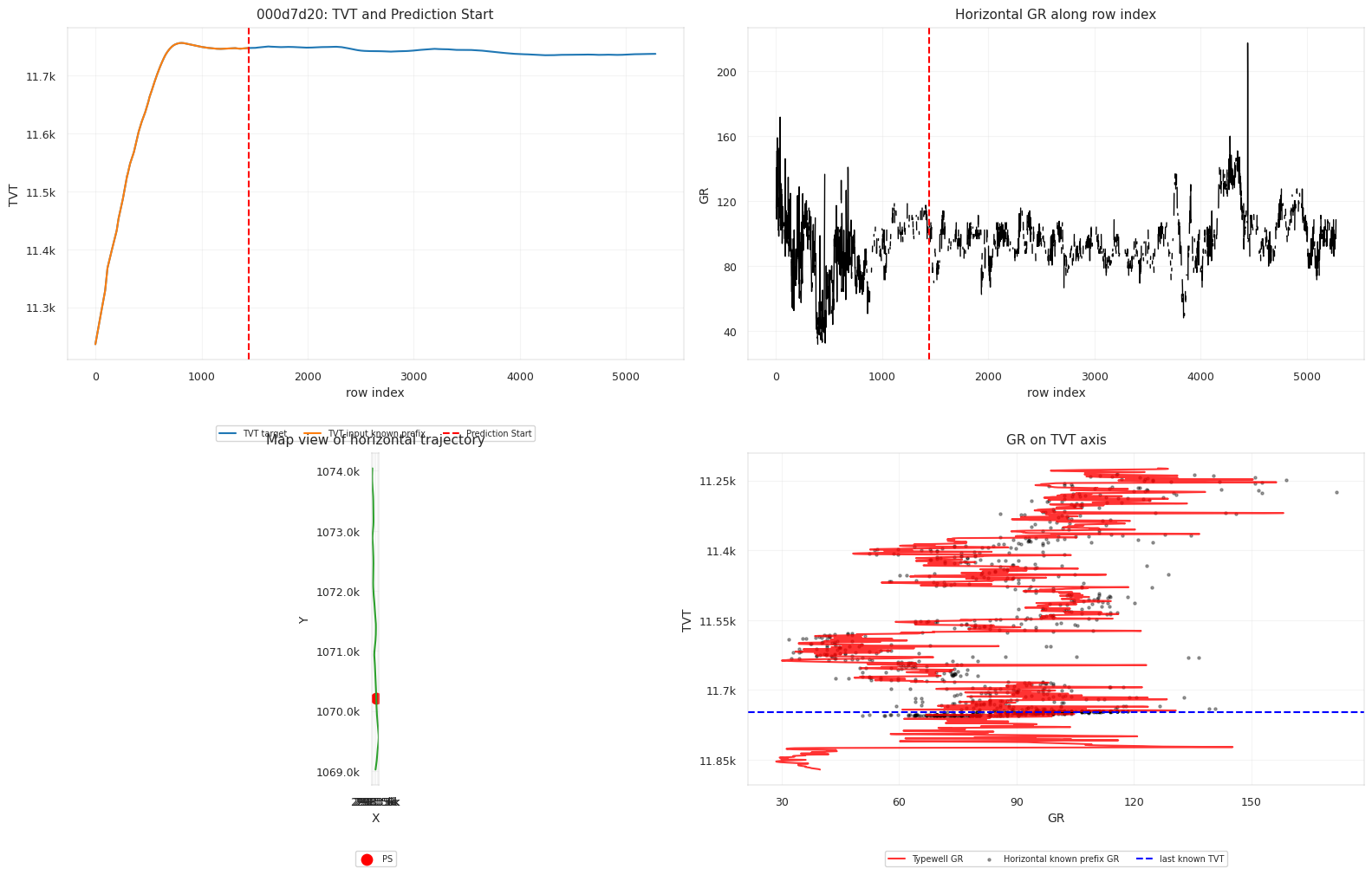
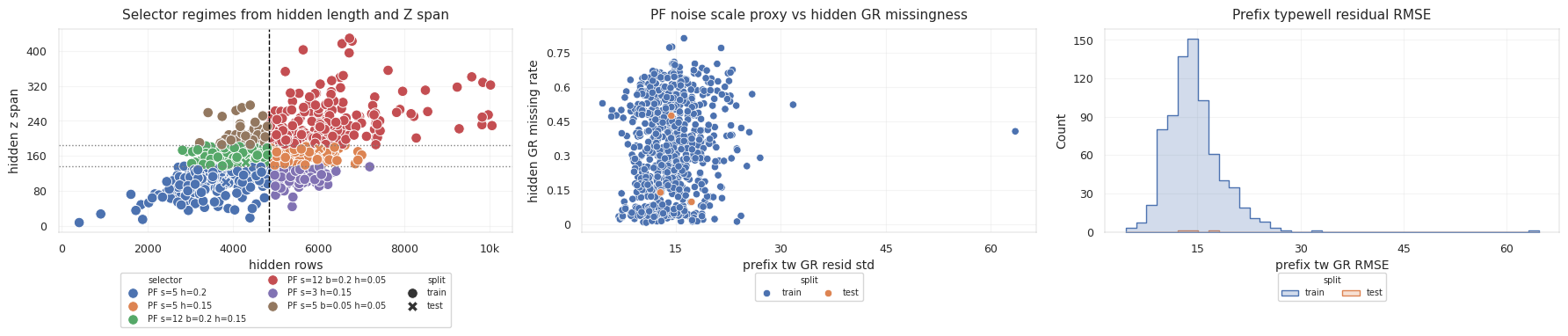
테스트 시추공 세 개는 서로 다른 reliability regime을 보여줍니다.
| Test Well | Hidden Rows | Hidden Z Span | Hidden GR Missing Rate | Prefix Typewell GR Corr | Selector Variant |
|---|---|---|---|---|---|
000d7d20 | 3836 | 100.02 | 0.4734 | 0.7718 | pf_scale_5_hold_0.2 |
00bbac68 | 6014 | 176.49 | 0.1383 | 0.8274 | pf_scale_5_hold_0.15 |
00e12e8b | 4301 | 144.81 | 0.0972 | 0.9335 | pf_scale_12_beam_0.2_hold_0.15 |
세 번째 시추공은 앞부분 typewell correlation이 가장 좋으므로 GR 대비를 더 강하게 믿을 수 있습니다. 첫 번째 시추공은 hidden GR missingness가 크기 때문에 hold와 geometry에 더 기대는 편이 안전합니다.
selector variant는 이 판단을 압축해 붙인 이름입니다.
| Selector Component | 해석 |
|---|---|
pf_scale_3 or pf_scale_5 | GR evidence를 비교적 신뢰할 수 있을 때 쓰는 좁은 likelihood입니다. |
pf_scale_12 | GR/typewell match에 더 큰 tolerance가 필요할 때 쓰는 넓은 likelihood입니다. |
beam_0.2 | beam-aligned path를 반영하되 지배하지 않게 합니다. |
hold_0.15 or hold_0.2 | 증거가 약할 때 last-known anchor의 관성을 남겨 둡니다. |
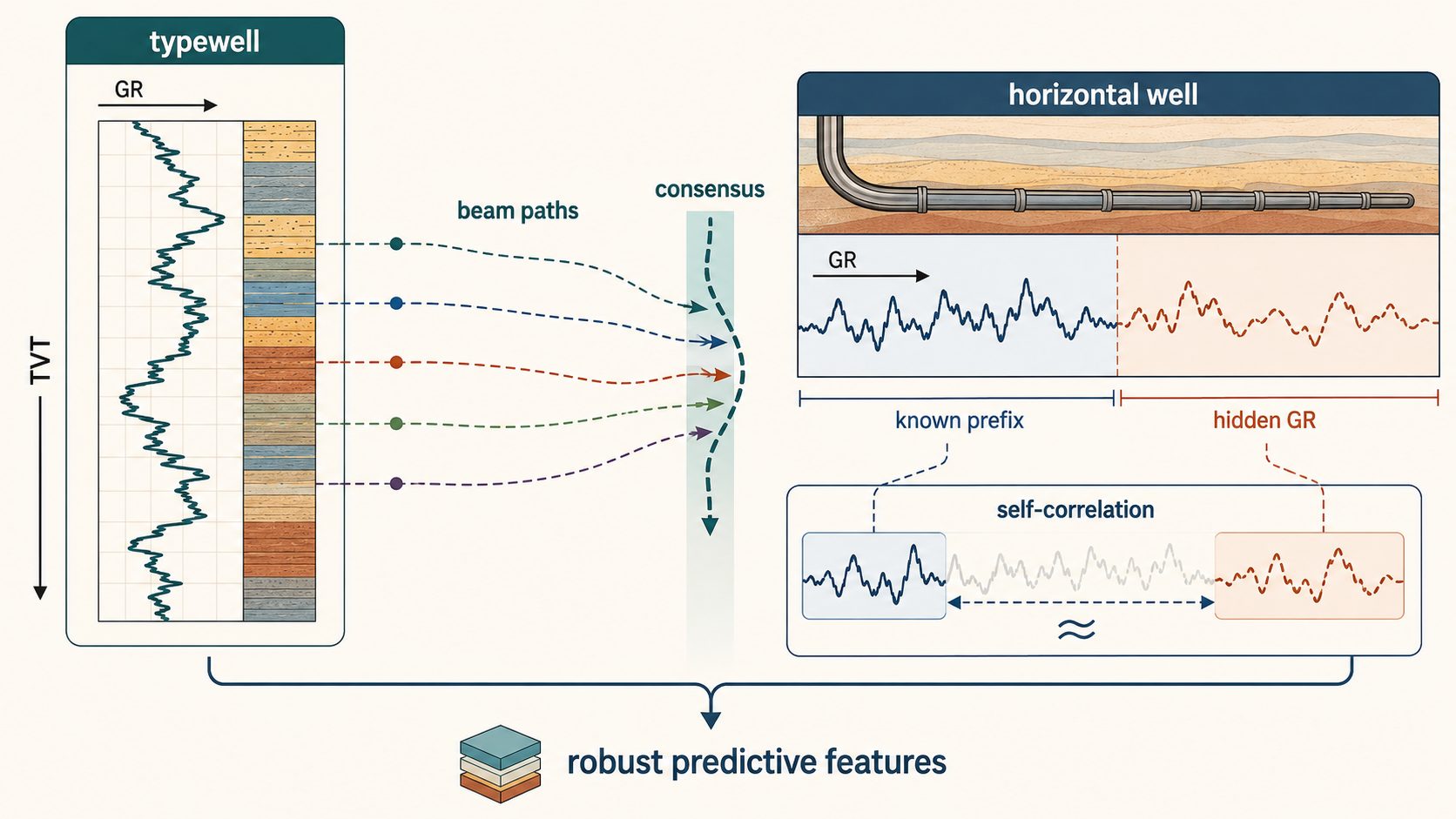
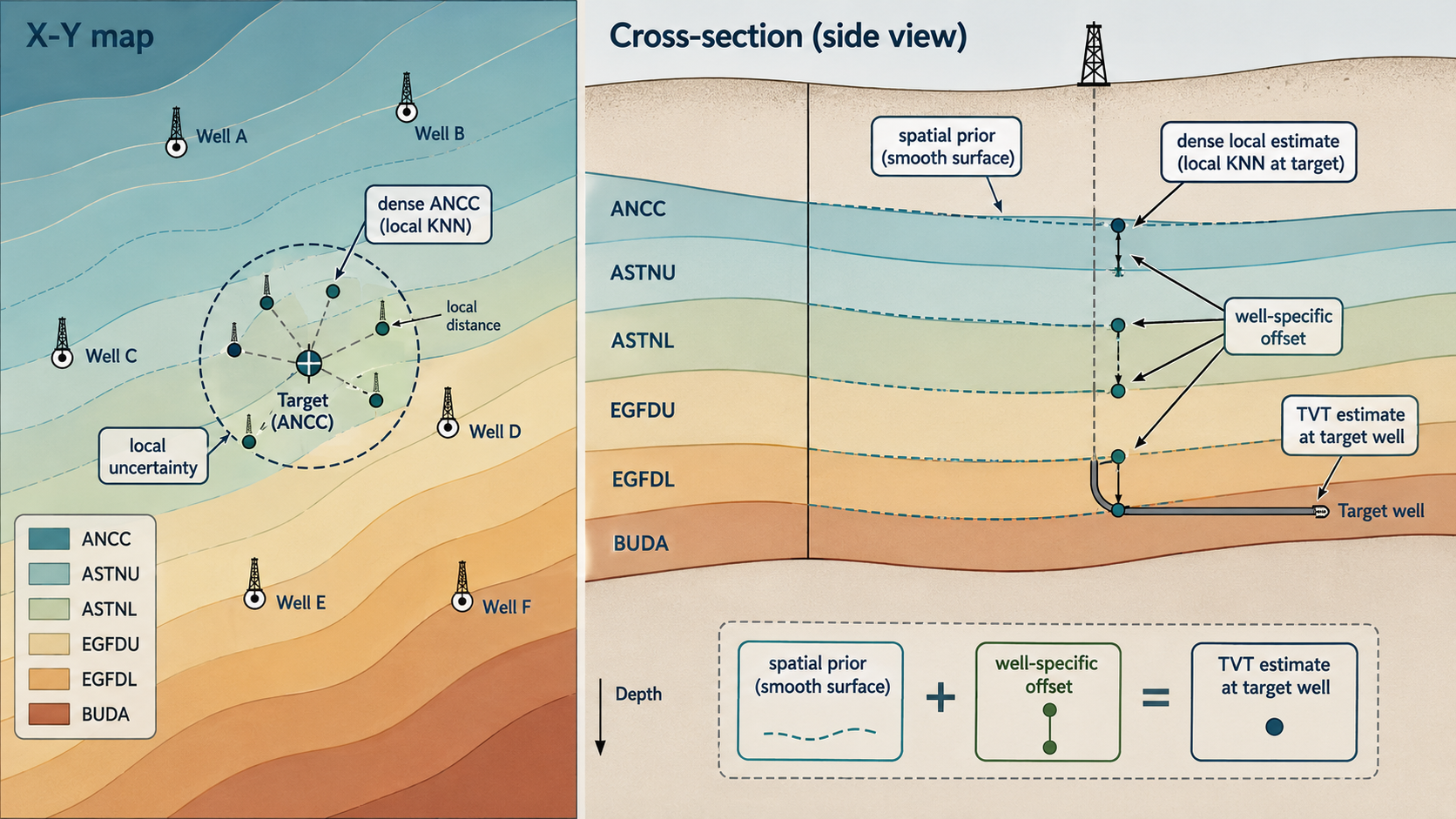
4. 지층 구조와 좌표의 관계
TVT는 Z와 따로 놀지 않습니다. 지층 구조를 생각하면 다음 관계가 자연스럽습니다.
같은 내용을 이렇게도 쓸 수 있습니다.
\[TVT_i + Z_i \approx S(X_i,Y_i) + b_w\]여기서 S(X,Y)는 공간상의 지층면, b_w는 시추공별 local offset입니다. 이 관계 덕분에 TVT만 보는 것보다 TVT + Z를 보는 편이 더 안정적일 때가 많습니다. 시추공이 기울어진 지층을 지나면 Z는 변하지만, TVT + Z는 지층면 기준의 좌표처럼 비교적 안정적으로 움직입니다.
수식을 말로 풀면 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
observed vertical position:
Z_i
estimated formation height at map location:
S(X_i, Y_i)
well-specific local offset:
b_w
stratigraphic coordinate:
TVT_i
지층이 거의 평평하면 S(X,Y)가 천천히 변하므로 anchor가 강하게 유지됩니다. 반대로 지층이 기울어져 있으면 constant-TVT 경로는 설득력이 떨어집니다. 이때 앞부분 구간이 시추공별 offset인 b_w를 추정하는 데 쓰입니다.
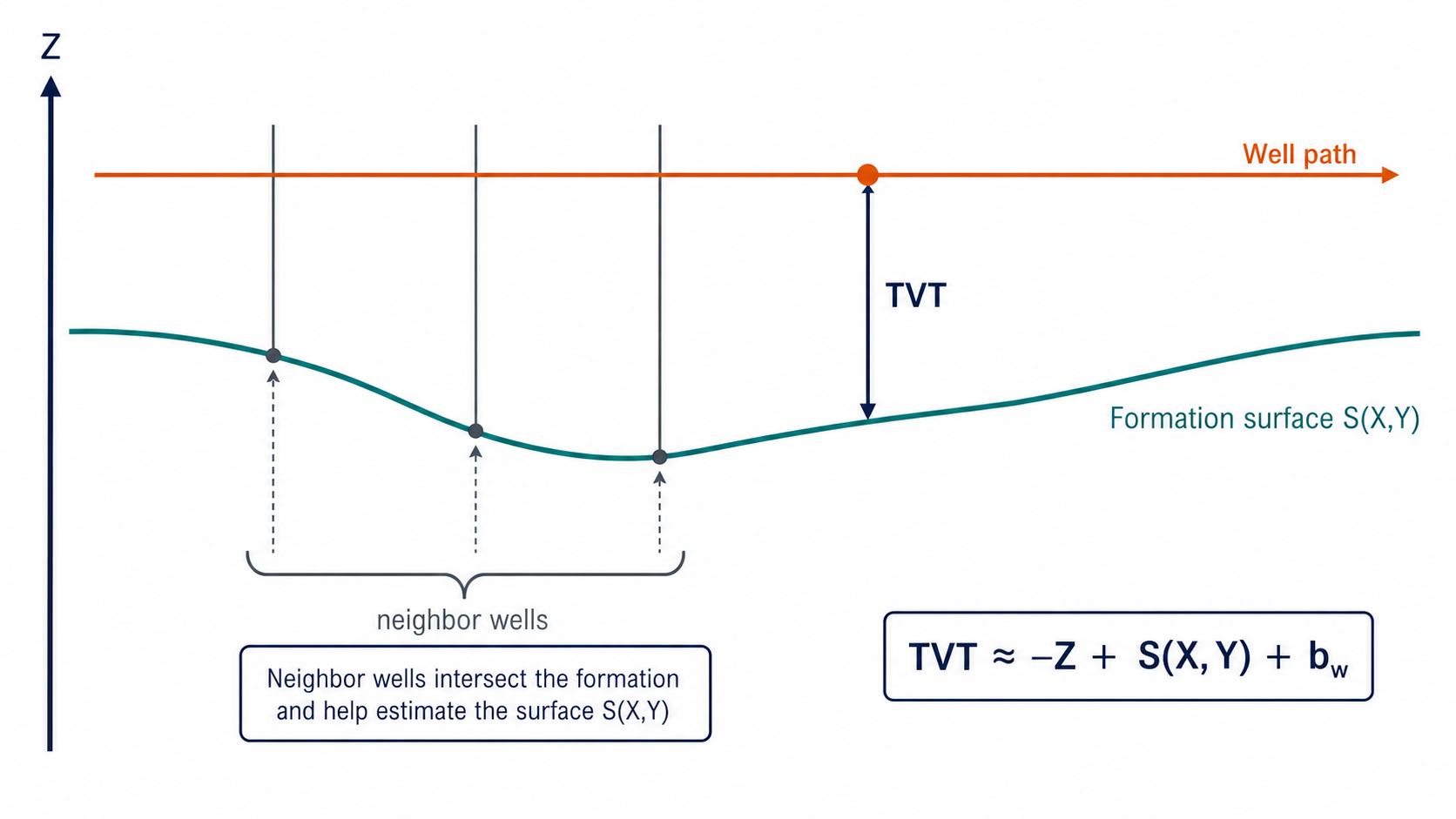
지층면을 안전하게 쓰려면 다음 순서를 따릅니다.
1
2
3
4
5
6
7
8
# fit only on training-fold wells
formation_model.fit(train_fold_xy, train_fold_formation_top)
# project validation or test rows from observable X/Y
formation_hat = formation_model.predict(row_xy)
# combine with row Z and prefix offset
tvt_estimate = -z + formation_hat + prefix_bias
train horizontal file에 있는 formation column을 직접 쓰는 건 위험합니다. test horizontal file에는 그 값이 없기 때문입니다. EDA에서 지질적 의미를 확인하는 데 쓰는 건 괜찮지만, 모델에는 fold 안에서 재현 가능한 surface estimator로 만든 값만 넣어야 합니다.
이 변환에는 두 가지 의미가 있습니다. 첫째, test 시점에도 같은 변수를 만들 수 있습니다. 둘째, validation에도 실제 추론과 같은 수준의 추정 오차가 반영됩니다.
유효한 신호는 formation top 원값 자체가 아니라, 추정한 surface를 투영한 뒤의 residual geometry입니다.
\[\epsilon^{formation}_i = (TVT_i + Z_i) - \hat{S}(X_i,Y_i)\]앞부분에서는 이 residual이 local offset을 추정하고, 후반 구간에서는 같은 estimated surface가 정답값을 보지 않는 trajectory prior가 됩니다.
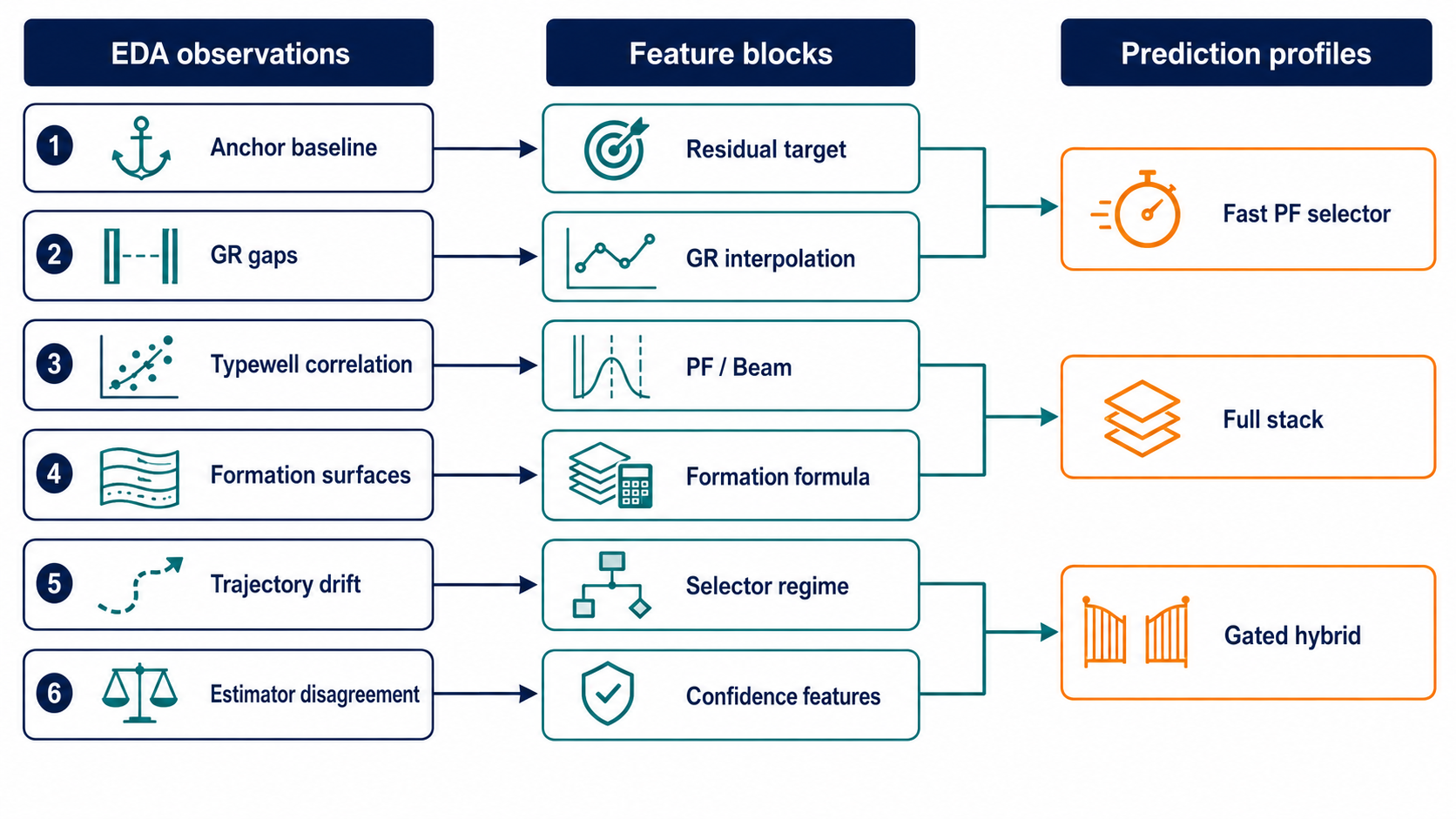
5. EDA 신호를 모델 변수로 바꾸는 과정
EDA에서 발견한 것들이 곧바로 모델 변수로 들어가는 건 아닙니다. 먼저 지질적인 해석으로 변환되고, 그 다음에 재현 가능한 모델 변수로 만들어져야 합니다.
| 관찰 | 지질적 해석 | 모델 변수 |
|---|---|---|
| 숨겨진 후반 구간이 길고 하나로 이어져 있습니다 | 행별 예측보다 경로 예측이 중요합니다 | tail_frac, md_since_last_known, fade-in |
| row별 TVT 변화가 작습니다 | 실제 경로는 대체로 smooth해야 합니다 | slope clipping, smoothing |
| 일부 well은 tail TVT range가 큽니다 | anchor만으로는 부족합니다 | PF, beam, DTW, formation drift |
| GR 결측 구간이 깁니다 | observation likelihood가 약합니다 | missing-rate features, hold weight |
| 앞부분 GR과 typewell GR mismatch가 큽니다 | typewell 대비 신뢰도가 낮습니다 | prefix correlation, RMSE, residual std |
TVT + Z가 안정적입니다 | formation-relative coordinate가 존재합니다 | formation-plane/top estimates |
| 같은 well 겹침이 있습니다 | 공개 점수만 좋아지는 지름길과 비공개 일반화 risk가 함께 존재합니다 | 겹침 활용 모드와 일반화 모드 분리 |
예를 들어 TVT가 매끄럽다는 관찰은 다음과 같은 흐름으로 변환됩니다.
1
2
3
4
5
6
7
8
Plot:
tail TVT is smooth with rare jumps
Geological statement:
plausible hidden paths should have bounded slope
Feature or postprocess:
train-derived slope quantile, fade-in, slope clipping
GR gap도 마찬가지입니다.
1
2
3
4
5
6
7
8
Plot:
some hidden tails contain long GR NaN runs
Geological statement:
observation likelihood is weaker inside gaps
Feature or postprocess:
missing-rate flags, longest-gap features, hold weight, lower alignment confidence
이 단계를 거치면 EDA 결과가 무작정 모델 변수로 들어가는 걸 막을 수 있습니다. test 시점에 재현할 수 없는 값은 EDA 수준에서만 확인하고 넘어가야 합니다.
시추 궤적에서 나오는 기본 변수는 다음과 같습니다.
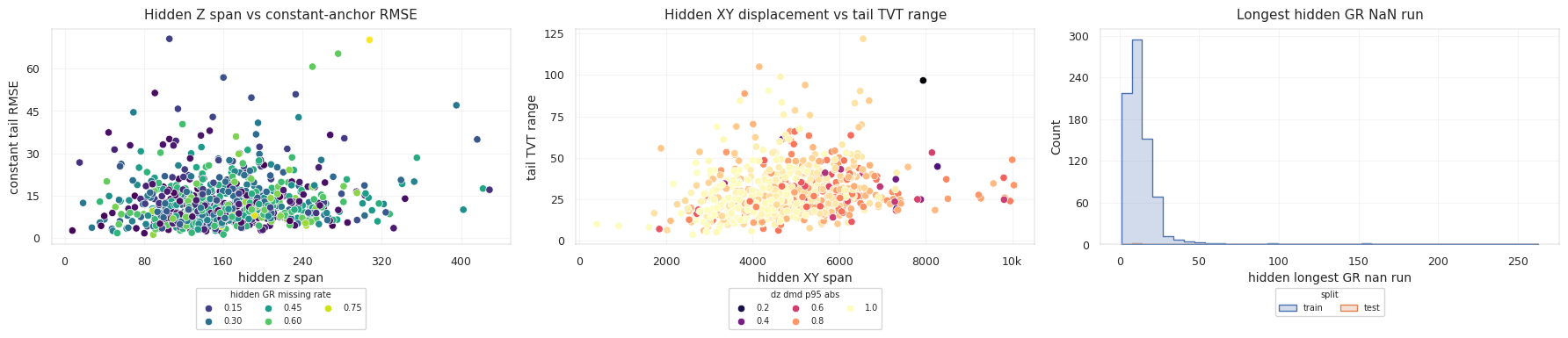
\[\frac{dZ}{dMD} = \frac{Z_i - Z_{i-1}}{MD_i - MD_{i-1}}\] \[dXY_i = \sqrt{(X_i-X_{i-1})^2 + (Y_i-Y_{i-1})^2}\]curvature는 진행 방향 벡터의 변화를 통해 추정합니다. 이 값들은 target 자체가 아니라, 시추공이 공간에서 어떻게 움직이는지를 나타내는 값입니다. TVT가 얼마나 빠르게 변할 수 있는지에 대한 prior로 활용됩니다.
| Geometry Signal | TVT에 주는 제약 |
|---|---|
Small hidden_z_span | 수직 이동이 작아 anchor가 더 그럴듯합니다. |
Large hidden_z_span | formation crossing이나 drift 가능성이 커집니다. |
| Stable azimuth | lateral 방향의 구조 변화가 더 매끄럽다고 볼 수 있습니다. |
| High curvature | local steering change가 단순 경로를 깨뜨릴 수 있습니다. |
Long MD tail | 작은 bias도 길게 누적될 수 있습니다. |
GR quality는 observation model을 조절합니다. 긴 결측 구간은 flat TVT의 증거도 아니고 sharp drift의 증거도 아닙니다. 단지 정보가 부족한 구간입니다. PF나 beam path는 이런 구간에서 GR likelihood를 덜 믿고, smoothness와 geometry prior에 더 기대야 합니다.
1
2
3
4
5
6
7
8
observed GR:
update path likelihood
missing GR:
propagate path under smoothness and geometry priors
long missing GR:
increase uncertainty and shrink corrections
TVT는 대체로 smooth하지만, 그렇다고 완전히 단순하지는 않습니다. row별 변화량의 중앙값은 작지만, 드물게 jump가 생기고 장거리 drift도 존재합니다. slope clipping은 이를 반영한 장치입니다. 임의로 곡선을 매끄럽게 만드는 게 아니라, training distribution에서 관측된 TVT 변화 속도를 기준으로 예측 경로를 제한하는 방식입니다.
1
2
Most true paths do not move faster than this per-row rate.
Predictions may move, but must justify movement through many consistent rows.
Typewell inventory와 prefix diagnostic은 GR 대비를 얼마나 신뢰할지 결정하는 근거가 됩니다.
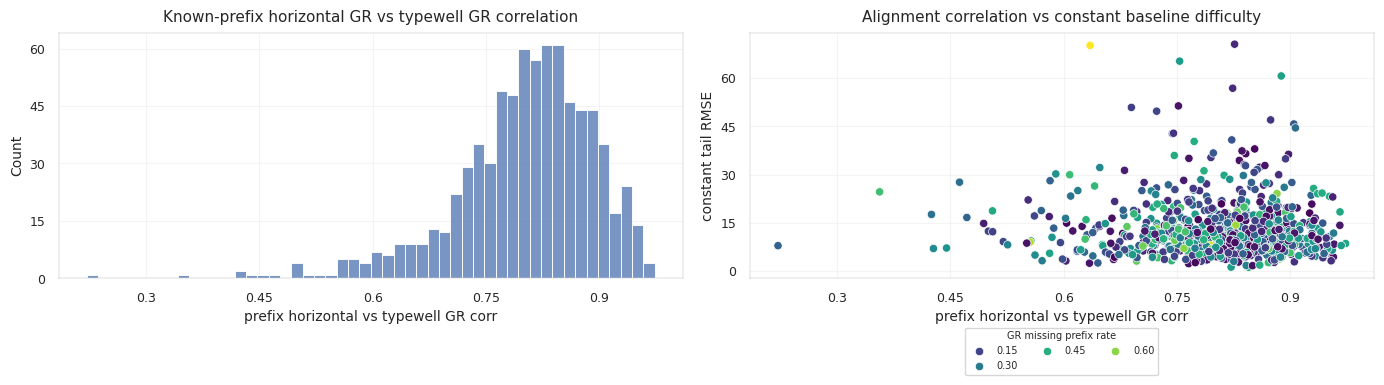
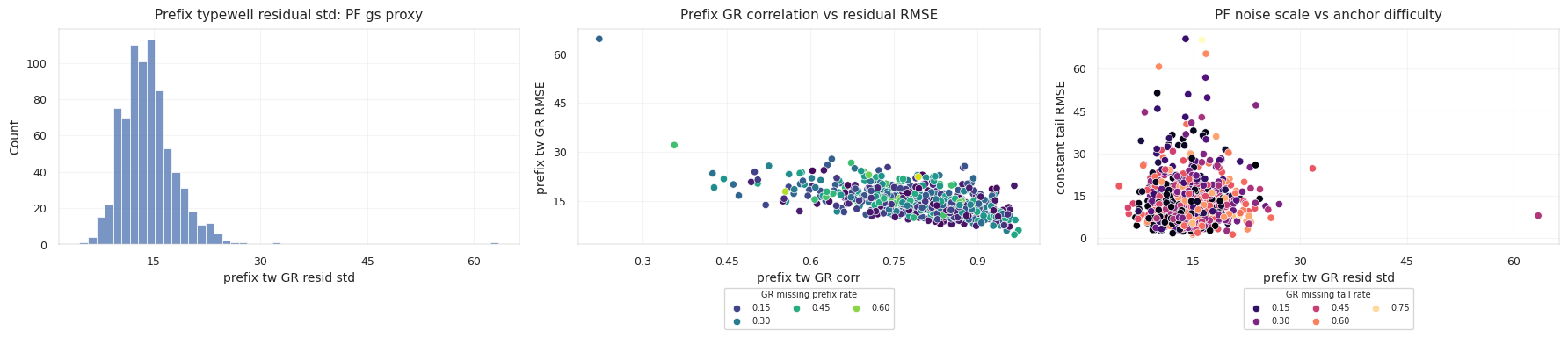
constant-anchor baseline은 반드시 봐야 하는 기준점입니다. 많은 시추공이 last known TVT 근처에 머물기 때문에, 모델이 drift를 만들려면 그만한 근거가 있어야 합니다. 반대로 실제로 움직이는 well에서는 다음 신호들이 필요합니다.
| Anchor가 실패하는 이유 | 필요한 신호 |
|---|---|
| TVT가 formation dip을 따라 drift합니다 | X/Y/Z formation surface, trajectory slope |
| GR pattern이 다른 layer로 이동합니다 | typewell 대비, DTW, beam, PF |
| 앞부분 offset이 misleading합니다 | nearby-well signal, formation residual correction |
| 긴 tail에서 작은 drift가 누적됩니다 | gradual residual model, fade-in |
| GR이 missing 또는 ambiguous합니다 | hold path, uncertainty-aware gate |
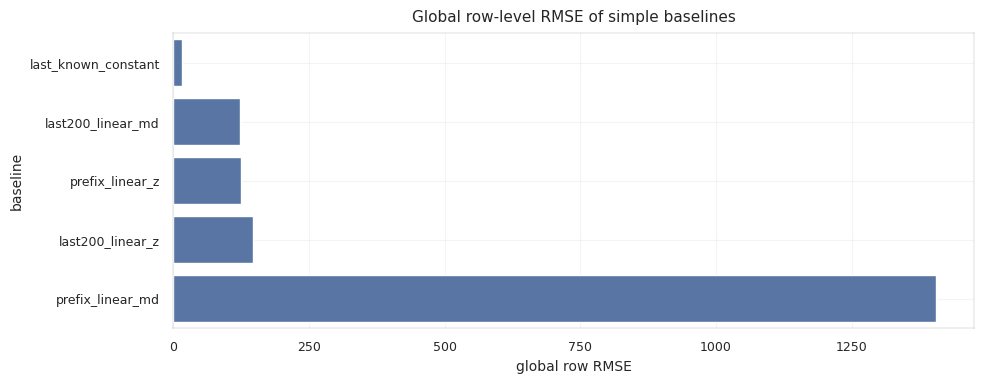
metric은 row-weighted이므로 긴 tail이 점수를 강하게 지배합니다. 그래도 well 단위 진단은 필요합니다. 아주 긴 well 몇 개가 짧은 well의 systematic failure를 가릴 수 있기 때문입니다.
\[RMSE_{row} = \sqrt{ \frac{1}{N} \sum_i (\hat{T}_i - T_i)^2 }\] \[RMSE_{well} = \frac{1}{W} \sum_w \sqrt{ \frac{1}{n_w} \sum_{i \in w} (\hat{T}_i - T_i)^2 }\] 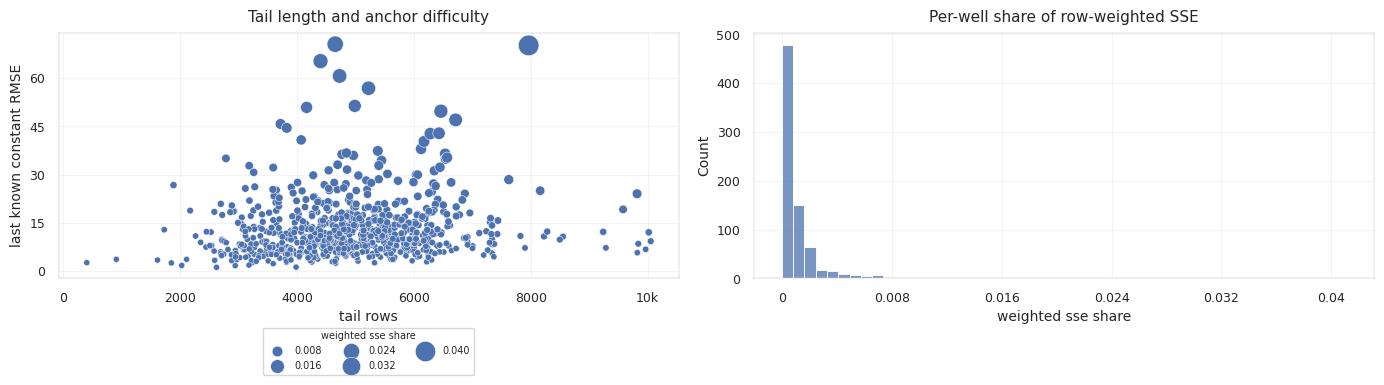
curve-level diagnostic, dense surface estimate, nearby-well spatial signal, representative well plot은 예측값을 바로 가져다 쓰기 위한 것이 아니라, 신뢰도를 판단하는 근거로 활용합니다.
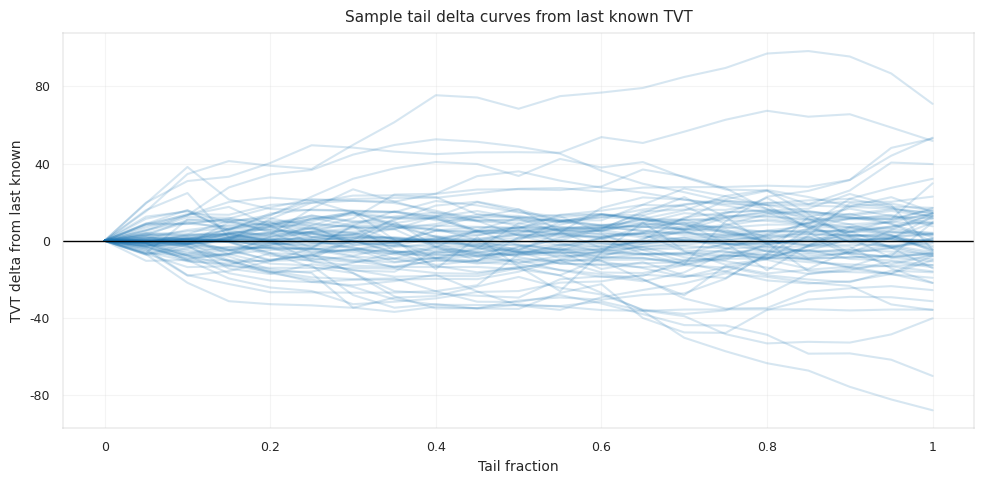
최종 변수 파이프라인은 EDA 해석과 데이터 누수 정책을 함께 묶어 둡니다.
6. 변수 사용 정책
모델 변수 묶음은 정보 사용 정책에 따라 구분합니다.
| Feature Set | Policy | Feature Count |
|---|---|---|
causal_base | strict | 39 |
prefix_context | strict | 60 |
typewell_alignment | strict | 108 |
calibrated_typewell_alignment | strict | 137 |
offline_prefix_context | offline | 115 |
offline_typewell_alignment | offline | 163 |
offline_calibrated_typewell_alignment | offline | 192 |
offline_candidate_path_alignment | offline | 263 |
offline_candidate_path_calibrated_alignment | offline | 292 |
offline_formation_plane_alignment | offline | 223 |
offline_formation_top_alignment | offline | 246 |
offline_beam_candidate_path_alignment | offline | 298 |
offline_super220_alignment | offline | 220 |
offline_compact_lgbm_style | offline | 83 |
offline_compact_lgbm_formation_style | offline | 143 |
offline_compact_lgbm_formation_top_style | offline | 166 |
선택한 strict feature set은 calibrated_typewell_alignment입니다.
| Setting | Value |
|---|---|
| feature count | 137 |
| shrinkage alpha | 0.81183 |
| fade-in tau MD | 200 |
| slope clip | True |
| slope quantile | 0.9 |
저장된 best offline feature family는 offline_candidate_path_alignment이며, 더 강한 shrinkage를 사용합니다.
| Setting | Value |
|---|---|
| feature count | 263 |
| shrinkage alpha | 0.94115 |
| fade-in tau MD | 200 |
| slope clip | True |
| slope quantile | 0.9 |
구분은 단순합니다.
1
2
strict features test drilling-time robustness
offline features exploit full provided test covariates without touching hidden targets
strict feature는 실시간 drilling에 가까운 보수적 설정을 확인하기 위한 묶음입니다. offline feature는 Kaggle test 파일에 이미 제공된 전체 covariate path를 활용하되, 숨겨진 TVT 정답값은 보지 않습니다.
7. 검증 방식
검증에서 답해야 할 질문은 이겁니다.
1
2
Can the estimator recover the hidden TVT tail of a well
whose tail labels were not visible during fitting?
row random split은 이 질문에 답이 되지 않습니다. 같은 시추공 안의 행들은 서로 강하게 연결되어 있습니다. 이미 인접한 행의 궤적, GR context, 지층 위치를 본 상태라면, 모델은 처음 보는 well을 예측하는 게 아니라 같은 well 안에서 interpolation을 하는 셈이 됩니다.
따라서 검증 단위는 행이 아니라 well입니다.
1
2
3
4
5
6
7
8
9
groups = train_tail["well_id"]
for fit_idx, valid_idx in GroupKFold(n_splits=5).split(train_tail, groups=groups):
fit_rows = train_tail.iloc[fit_idx]
valid_rows = train_tail.iloc[valid_idx]
fit_package = fit_all_estimators(fit_rows)
valid_pred = infer_hidden_tail(valid_rows, fit_package)
fold_rmse = rmse(valid_rows["TVT"], valid_pred)
fold 안에서도 최종 추론과 같은 구조를 유지해야 합니다.
| Object | Fold Behavior | Final Behavior |
|---|---|---|
| Typewell calibration | held-out validation well의 known prefix만으로 fit | test well의 known prefix만으로 fit |
| Formation surface | training-fold well에서 fit | 허용된 모든 training well에서 fit |
| PF/beam/DTW paths | held-out covariate와 typewell curve로 생성 | test covariate와 typewell curve로 생성 |
| Residual model | fit-fold residual로 train | 전체 training residual로 train |
| Postprocess policy | globally select 후 held-out prediction에 적용 | 선택된 policy를 test prediction에 적용 |
공개 점수와 비공개 점수를 해석하는 건 여기에 기반합니다. 어떤 feature는 GroupKFold에서 좋아도 same-well overlap에 의존하면 private에서는 약할 수 있습니다. 반대로 full test GR/trajectory를 쓰더라도 정답값을 보지 않는 방식이면 offline 환경에서도 안전하고 private에도 견고할 수 있습니다.
| Evidence | 답하는 질문 |
|---|---|
| Strict GroupKFold | 앞부분과 현재/과거 정보만으로 작동하는가? |
| Offline target-free GroupKFold | 숨겨진 TVT 없이 전체 covariate path가 얼마나 도움이 되는가? |
| Public same-well enabled submission | visible leaderboard에서 관측 가능한 public overlap이 얼마나 도움이 되는가? |
8. PF, Beam, DTW와 선택 모드
예측기는 하나의 경로가 아니라 여러 후보 경로의 집합입니다.
| 후보 경로 | 의미 |
|---|---|
hold | 마지막으로 알려진 TVT_input 근처에 머뭅니다. |
PF | 가능한 TVT state를 particle filter로 추적합니다. |
beam | 여러 plausible path를 beam search로 유지합니다. |
DTW | horizontal GR과 typewell GR의 sequence를 맞춥니다. |
| formation path | X/Y/Z를 안전하게 추정한 formation surface로 TVT에 연결합니다. |
| same-well physical | train/test에 같은 well ID가 있을 때 geometry 겹침을 이용합니다. |
각 경로는 서로 다른 가정을 담고 있습니다. hold는 well이 같은 지층 위치에 머문다고 가정합니다. flat tail에서는 강하지만, drift tail에서는 약합니다. formation path는 공간 구조를 신뢰합니다. GR이 없어도 작동하지만, local offset에는 약할 수 있습니다. GR 대비 path는 typewell barcode가 충분한 정보를 준다고 봅니다. 반복되는 GR motif가 있으면 false match가 생길 수 있습니다. PF는 이 불확실성을 너무 빨리 하나의 답으로 접지 않고 순차적으로 끌고 갑니다.
particle filter의 state는 다음과 같습니다.
\[s_i = TVT_i\]transition prior는:
\[p(s_i \mid s_{i-1}) \propto \exp \left( - \frac{(s_i - s_{i-1} - \mu_i)^2}{2\tau_i^2} \right)\]observation likelihood는:
\[p(GR_i \mid s_i) \propto \exp \left( - \frac{(GR_i - GR^{typewell}(s_i))^2}{2\sigma_{GR,w}^2} \right)\]mu_i는 geometry나 이전 path에서 기대되는 drift를 반영하고, sigma_GR,w는 앞부분에서 calibration한 GR noise scale입니다. GR이 missing이면 observation likelihood가 납작해지므로 transition prior, hold, formation path가 더 중요해집니다.
DTW recurrence는 다음과 같습니다.
\[D(i,j) = (GR^{h}_i - GR^{tw}_j)^2 + \min \left[ D(i-1,j-1), D(i-1,j), D(i,j-1) \right]\]DTW는 TVT label이 아니라 GR sequence를 맞추므로 정답값을 보지 않는 방법입니다. 위험은 정답 유출이 아니라, noisy/missing GR을 과신하는 데 있습니다.
1
2
horizontal segment A may correspond to a short typewell interval
horizontal segment B may correspond to a longer typewell interval
이 유연성은 지층 대비에서 꼭 필요합니다. 하지만 반복되는 GR motif가 있으면 그럴듯해 보이지만 틀린 경로를 고를 수 있습니다. 그래서 DTW는 단독으로 쓰는 정답이 아니라, 후보 신호 중 하나로 활용합니다.
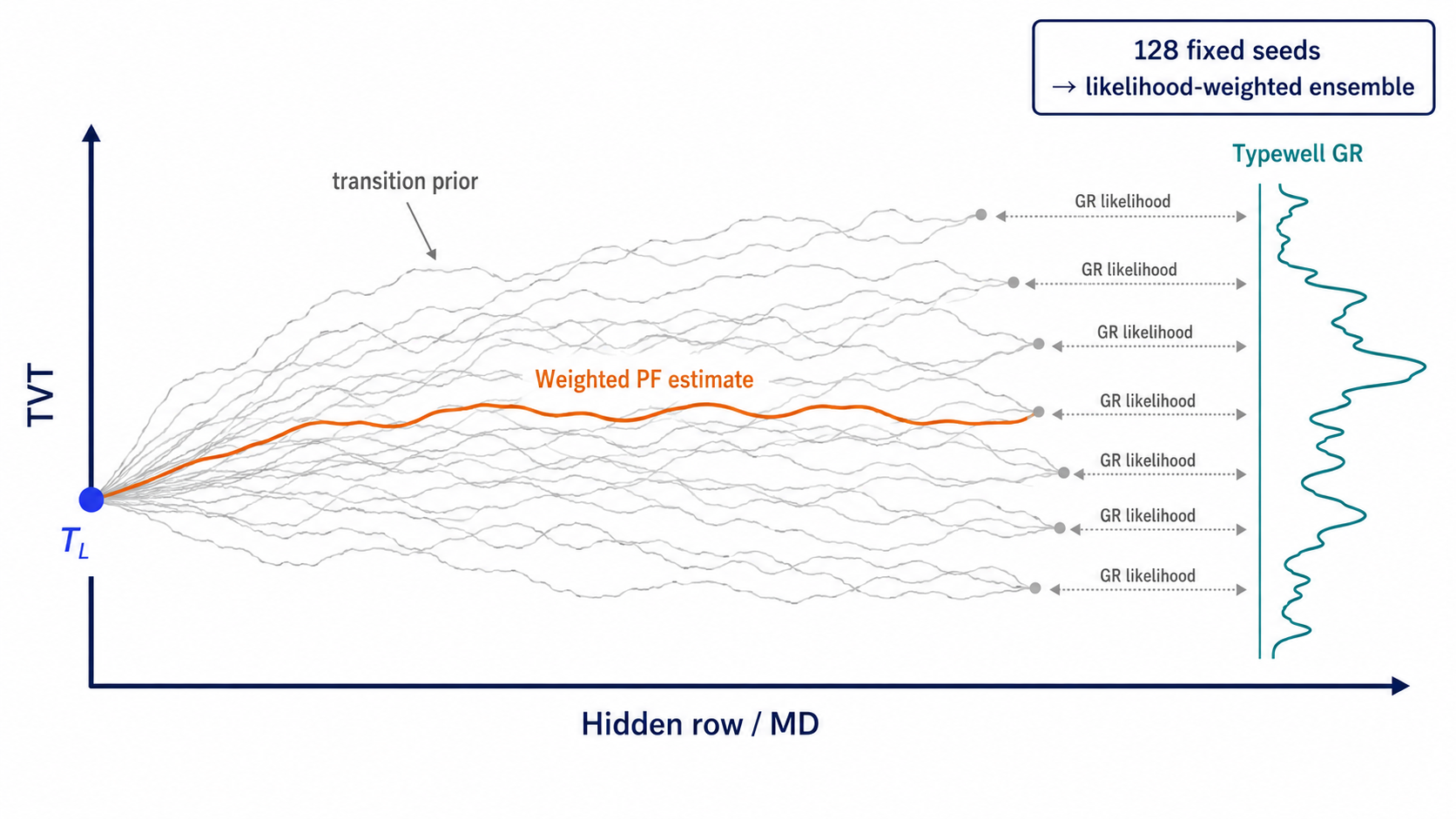
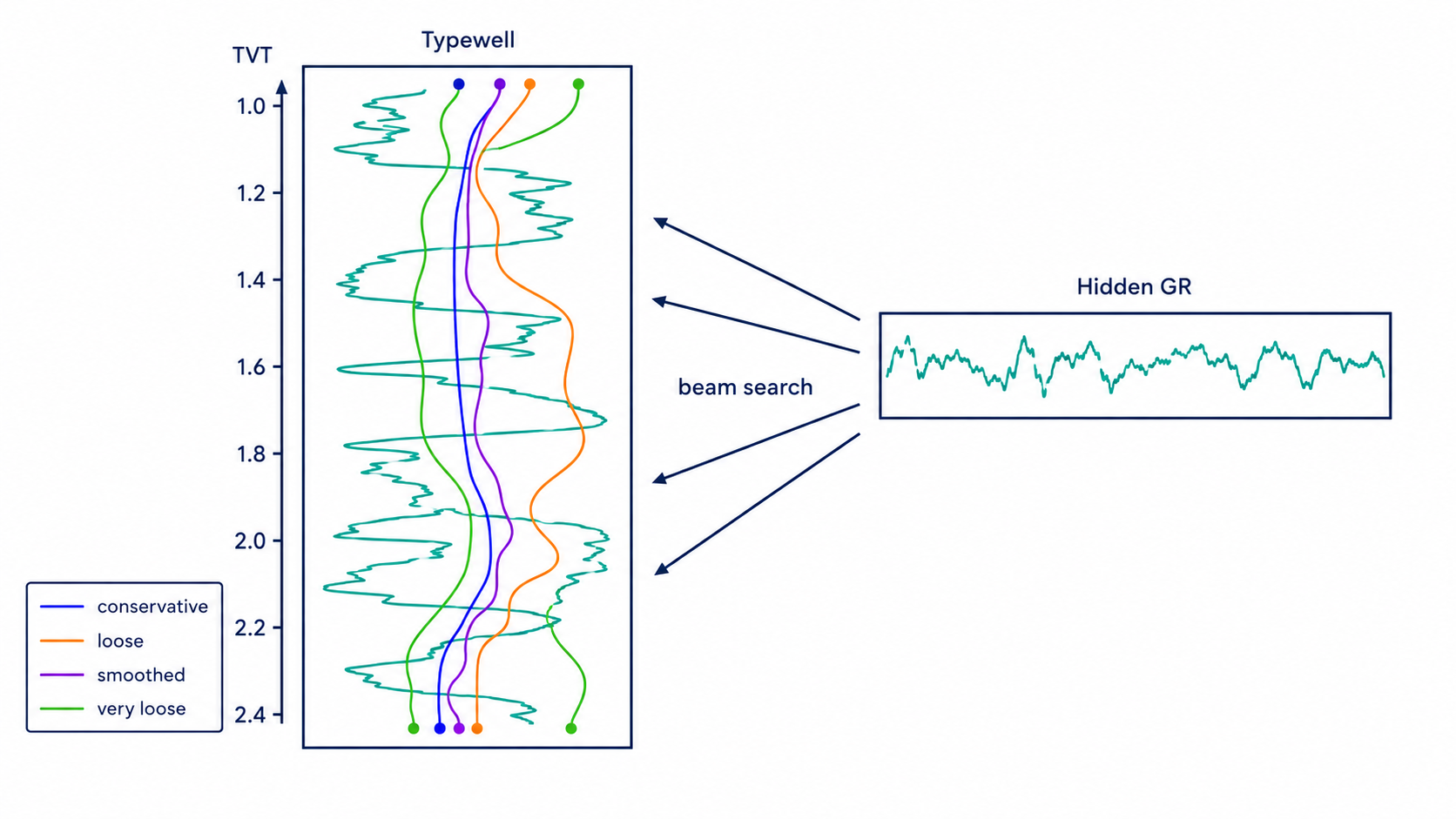
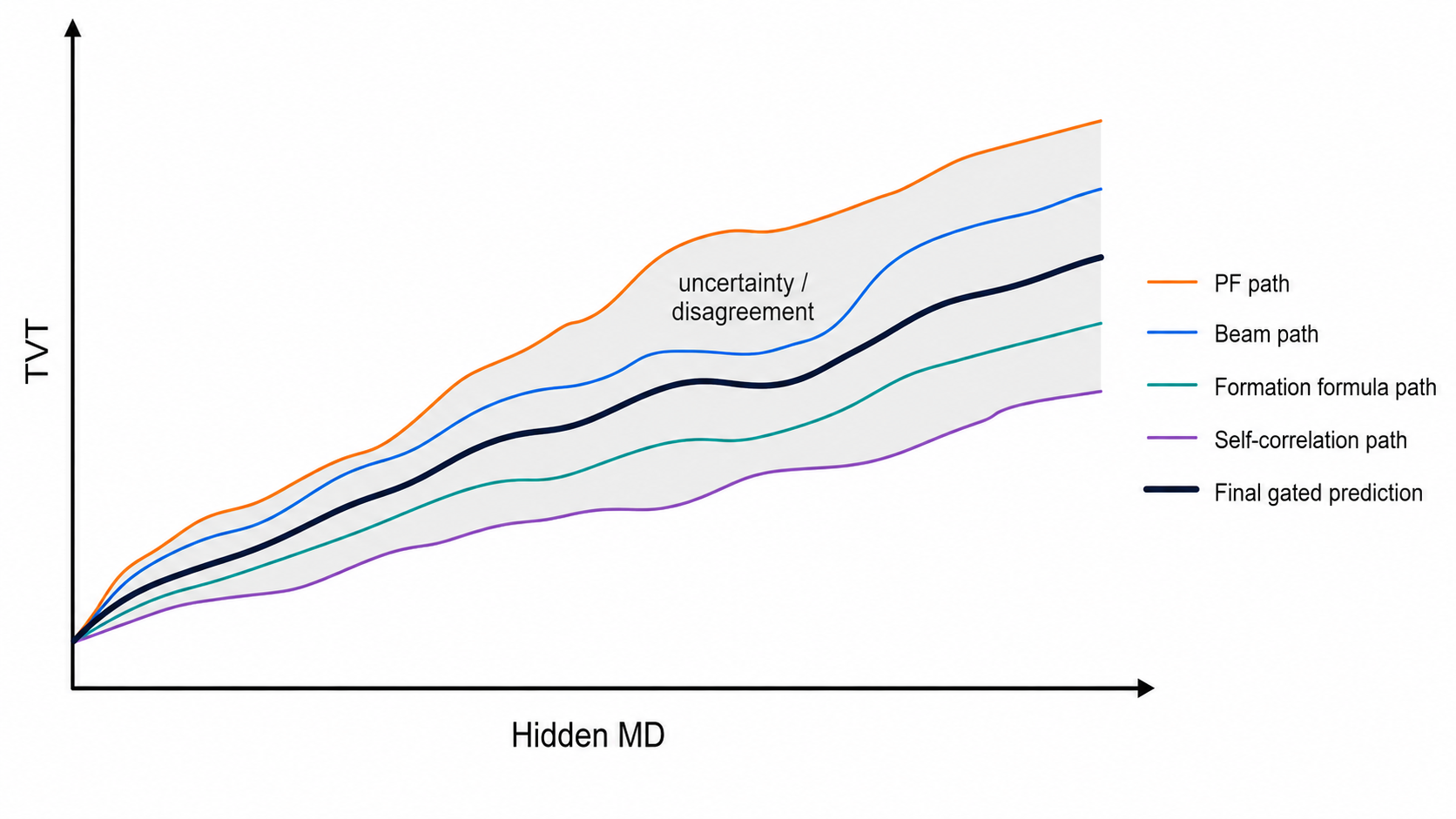
추정기들이 서로 동의하지 않을 때는 그 차이 자체가 uncertainty signal이 됩니다.
| 불일치 | 해석 |
|---|---|
| PF close to beam, far from hold | GR evidence가 drift를 일관되게 지지합니다. |
| PF close to hold, beam far away | Beam이 false GR match를 따라갈 수 있습니다. |
| Formation close to hold, GR paths far away | GR motif가 ambiguous하거나 local calibration이 어긋났을 수 있습니다. |
| All paths spread out | uncertainty가 크므로 shrinkage와 작은 correction을 선호합니다. |
| Same-well physical far from target-free paths | public overlap을 이용한 지름길이 일반 지질 추정과 충돌합니다. |
selector regime map은 well context별로 어떤 선택 모드가 그럴듯한지 보여줍니다.
registry audit는 feature family와 policy를 계속 확인하게 해줍니다.
9. 제출 프로필
제출 모드는 단순 실행 옵션이 아니라 어떤 위험을 감수할지 정하는 장치입니다.
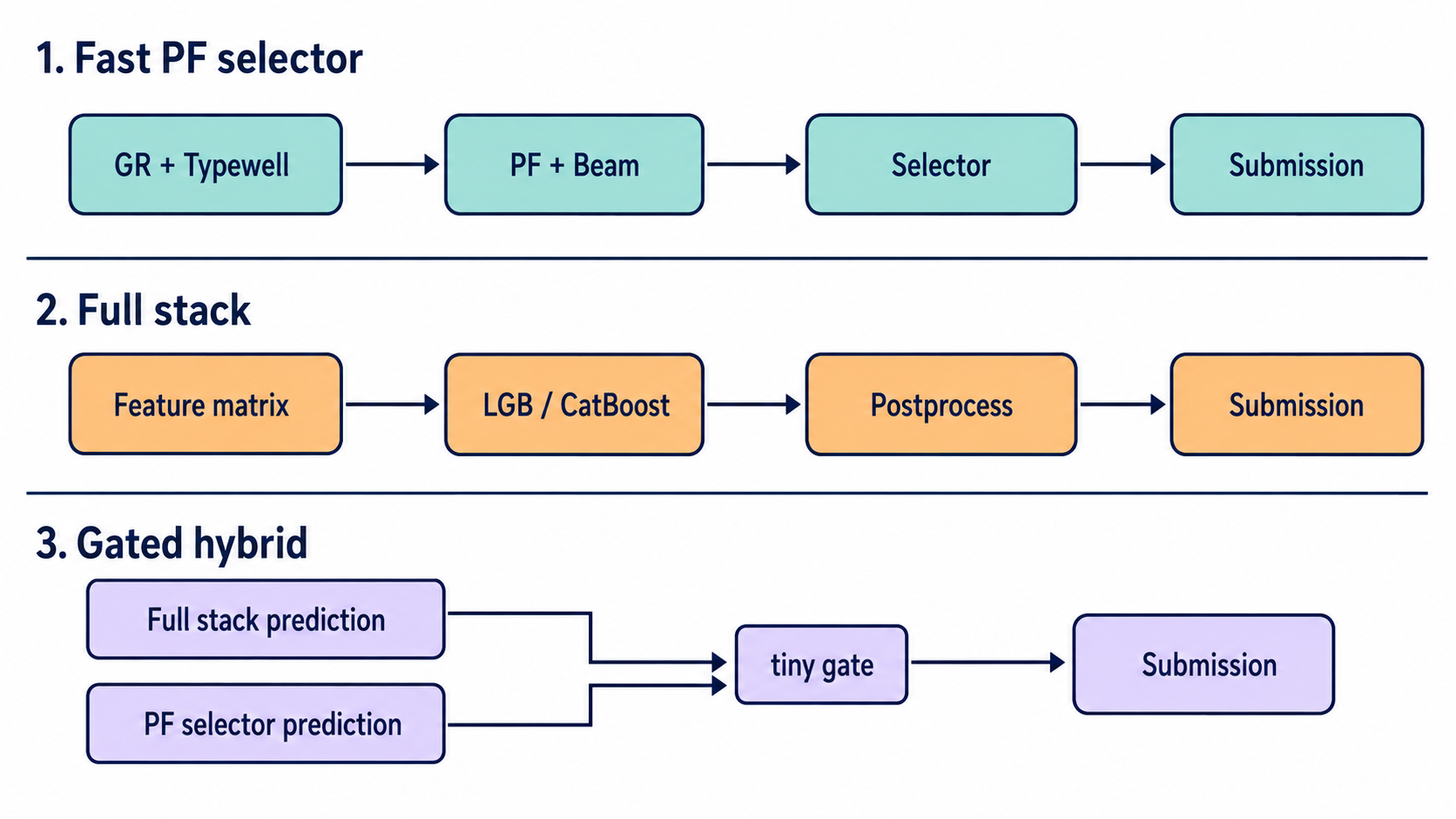
| Profile | 해석 |
|---|---|
fast_pf_selector | 정답값을 보지 않는 PF/beam selector입니다. |
fast_pf_selector_128 | 같은 family에서 PF seed를 늘린 버전입니다. |
model_package_only | PF/stack base 없이 packaged model inference만 실행합니다. |
pf_residual_gbdt_exact | public PF-residual GBDT를 그대로 재현하는 모드입니다. |
pf_residual_gbdt | median-guarded fill을 쓰는 guarded PF-residual GBDT입니다. |
full_stack_postproc | full target-free stack과 post-processing을 사용합니다. |
full_stack_sel15_gated | full stack에 작은 gated PF selector correction을 더합니다. |
full_stack_postproc_model_gated | post-processed stack에 gated model-package correction을 더합니다. |
full_stack_postproc_model_late | post-processed stack에 fixed-weight model-package correction을 더합니다. |
full_stack_sel15_gated_model_gated | selector blend에 gated model-package correction을 더합니다. |
full_stack_sel15_gated_model_late | selector blend에 late fixed-weight model correction을 더합니다. |
제출 모드는 크게 네 계열로 볼 수 있습니다.
| 계열 | Profiles | 핵심 질문 |
|---|---|---|
| PF selector | fast_pf_selector, fast_pf_selector_128 | residual model 없이 target-free path selector가 얼마나 강한가? |
| Model package | model_package_only | learned package가 test inference를 단독으로 재현할 수 있는가? |
| PF residual | pf_residual_gbdt_exact, pf_residual_gbdt | GBDT가 systematic PF bias를 얼마나 제거하는가? |
| Full stack plus correction | full_stack_* | 여러 target-free estimator와 sidecar correction이 base를 얼마나 안전하게 움직이는가? |
gated correction은 estimator 사이의 disagreement가 클 때 correction을 줄입니다.
\[g_i = \frac{g_{max}} {1 + \left(\frac{|\hat{T}^{selector}_i - \hat{T}^{stack}_i|}{s}\right)^2}\] \[\hat{T}^{final}_i = (1-g_i)\hat{T}^{stack}_i + g_i\hat{T}^{selector}_i\]model-package sidecar blend에도 같은 형태를 쓸 수 있습니다.
\[\operatorname{GateBlend}_i(A,B) = (1-G_i)A_i + G_iB_i\]fixed late blend는 더 단순합니다.
\[\hat{T}^{final}_i = (1-w)A_i + wB_i\]gate는 강한 추정기 두 개가 서로 다른 well에서 실패할 수 있다는 점을 반영합니다. blind average는 맞는 경로를 오히려 망칠 수 있습니다. disagreement-aware gate는 충돌이 큰 지점에서 correction을 작게 만듭니다.
10. PF 잔차 GBDT
guarded PF-residual 설정은 PF path를 기준으로 두고, 그 잔차를 tree model로 학습합니다.
\[R_i = T_i - \hat{T}^{PF}_i\]최종 형태는 다음과 같습니다.
\[\hat{T}^{final}_i = \hat{T}^{PF}_i + 0.40 f_{lgb}(x_i) + 0.40 f_{xgb}(x_i) + 0.20 f_{cat}(x_i)\]tree model은 물리적 경로를 대체하지 않습니다. PF가 체계적으로 높거나 낮게 빗나가는 경우를 보정합니다.
| 구성 요소 | 역할 |
|---|---|
| PF base | 정답값을 보지 않는 지질 경로를 제공합니다. |
| Residual features | reliability, geometry, prefix calibration, path disagreement를 설명합니다. |
| GBDT correction | GroupKFold validation 아래에서 예측 가능한 PF bias를 보정합니다. |
| Guarded fills | missing 또는 unstable feature가 극단적인 correction을 만들지 못하게 합니다. |
TVT를 직접 예측하면 well-level offset이나 row-position effect를 쉽게 학습하게 됩니다. 반면 PF residual을 예측하면 질문이 좁아집니다.
1
2
물리적으로 그럴듯한 PF 경로가 주어졌을 때,
그 경로가 언제 체계적으로 높거나 낮게 빗나가는가?
| 잔차 패턴 | 가능한 해석 |
|---|---|
| PF too flat after long Z drift | Formation dip이 충분히 반영되지 않았습니다. |
| PF overreacts inside GR gaps | Missing GR interpolation을 너무 믿었습니다. |
| PF shifted by a nearly constant offset | Prefix GR/typewell calibration 또는 formation offset bias입니다. |
| PF follows a false motif | Beam/DTW disagreement와 prefix correlation으로 신뢰도를 낮춰야 합니다. |
OOF 결과는 다음과 같습니다.
| Fold | Residual RMSE | Absolute TVT RMSE |
|---|---|---|
| 1 | 9.6520 | 9.6520 |
| 2 | 10.2444 | 10.2444 |
| 3 | 9.7082 | 9.7082 |
| 4 | 10.5604 | 10.5604 |
| 5 | 12.4396 | 12.4396 |
| Model | OOF Absolute RMSE |
|---|---|
| PF only | 11.0106 |
| PF + residual GBDT | 10.5696 |
correction은 물리적 prior를 보존할 만큼 작고, 반복적인 PF error를 흡수할 만큼은 큽니다.
fold 사이의 차이는 failure mode를 보여줍니다. 평균 RMSE만 보면 어떤 well group이 어려운지 알 수 없습니다. 이런 요인들을 따로 살펴봐야 합니다.
1
2
3
4
5
high GR missingness
weak prefix correlation
large hidden Z span
unusual formation offset
same-well branch unavailable
feature policy table은 데이터 누수 통제의 핵심입니다.
1
2
3
4
5
6
7
8
9
feature_policies = {
"anchor_residual": "strict",
"gr_quality": "target_free",
"prefix_typewell_calibration": "strict",
"pf_state_space": "target_free",
"beam_alignment": "target_free",
"selector_regime": "target_free",
"same_well_physical": "public_aggressive",
}
각 feature family에 policy label을 붙이면, 좋은 점수가 strict evidence, offline target-free evidence, public-aggressive evidence 중 어디에서 왔는지 해석할 수 있습니다.
11. OOF 산출물과 모델 패키지 추론
OOF prediction은 검증 증거입니다. 그 자체가 완전한 제출 엔진은 아닙니다.
OOF 산출물이 답하는 질문은 이렇습니다.
1
held-out training well에서 추정기가 어떻게 동작했는가?
정작 최종 제출에서 필요한 답은 다릅니다.
1
test well의 hidden row에 대해 이 추정기는 무엇을 예측하는가?
test row에는 OOF prediction이 없습니다. 따라서 재사용 가능한 package에는 test feature matrix를 다시 만들고, 모델을 실행하고, sample order로 정렬하는 장치가 들어 있어야 합니다.
| 층 | 내용 |
|---|---|
| Evidence artifact | OOF prediction, fold score, feature importance, validation diagnostic |
| Inference artifact | feature builder, fitted imputer, fitted model, profile config, postprocess config |
evidence layer는 검증 성능을 설명합니다. inference layer는 submission.csv를 만듭니다.
| 필요한 요소 | 이유 |
|---|---|
| Feature builder | test row에도 같은 target-free geometry, GR, PF, beam, formation feature가 필요합니다. |
| Prefix calibration | test well마다 자기 prefix GR/typewell reliability estimate가 필요합니다. |
| Safe imputers | formation과 spatial estimate는 validation label 없이 재현 가능해야 합니다. |
| Trained models | residual correction에는 최종 fitted LGB/XGB/CatBoost 또는 stack component가 필요합니다. |
| Sample alignment | sidecar 결과는 sample_submission.csv row order와 정확히 맞아야 합니다. |
| Blend policy | base와 sidecar prediction에는 고정된 off, late_linear, gated_late_linear 규칙이 필요합니다. |
package manifest는 재현을 위한 명세입니다.
1
2
3
4
5
6
7
8
9
10
11
package/
config.json
feature_registry.json
formation_surface.pkl
typewell_calibration.py
pf_config.json
beam_config.json
lgb_models/
xgb_models/
catboost_models/
postprocess.json
추론 흐름은 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
sample = pd.read_csv("sample_submission.csv")
base = build_target_free_base_submission(test_files, sample)
sidecar = run_model_package_inference(
test_horizontal_files,
test_typewell_files,
sample_submission=sample,
)
base = align_submission_to_sample(base, sample)
sidecar = align_submission_to_sample(sidecar, sample)
final = blend_base_and_sidecar(base, sidecar, mode=SIDECAR_MODE)
sidecar는 base를 대체하는 장치가 아닙니다. base는 PF-residual이나 full-stack target-free submission일 수 있고, sidecar는 다른 feature family로 학습한 model package일 수 있습니다. 최종 blend는 sidecar가 base를 얼마나 움직일 수 있는지만 제한합니다.
alignment guard는 필수입니다.
1
2
3
4
5
6
7
8
9
def align_submission_to_sample(frame, sample, label):
frame = frame[["id", "tvt"]].copy()
frame["id"] = frame["id"].astype(str)
aligned = sample[["id"]].merge(frame, on="id", how="left")
if aligned["tvt"].isna().any():
raise ValueError(f"{label}: missing predictions after id alignment")
return aligned
sidecar mode는 의도적으로 선택 가능하게 설계되어 있습니다.
| Sidecar 모드 | 동작 |
|---|---|
off | base submission을 그대로 둡니다. |
late_linear | sidecar estimate에 고정 late weight를 적용합니다. |
gated_late_linear | base/sidecar disagreement가 작을 때만 correction을 적용합니다. |
gated sidecar correction은 다음과 같습니다.
\[G_i = \frac{G_{max}} {1 + \left(\frac{|B_i - A_i|}{s}\right)^2}\] \[\hat{T}_i = (1-G_i)A_i + G_iB_i\]A_i는 base, B_i는 sidecar prediction, G_max는 correction budget, s는 disagreement scale입니다.
| 진단 항목 | 의미 |
|---|---|
| aligned row count | sidecar가 모든 sample row를 커버하는지 확인합니다. |
| missing IDs | package가 예측하지 못한 row가 있는지 봅니다. |
| mean absolute difference | sidecar가 base를 보통 얼마나 움직이는지 봅니다. |
| p95 absolute difference | correction의 상위 위험 구간을 봅니다. |
| effective gate mean | gating 이후 평균 sidecar weight입니다. |
| max correction | final blend가 허용하는 최대 이동량입니다. |
12. 스택 구성 논리
큰 stack은 정답값을 보지 않고 만든 여러 pseudo-TVT path를 결합합니다.
| 신호 | 역할 |
|---|---|
| Beam | typewell GR 위에서 discrete path search를 수행합니다. |
| DTW | horizontal GR과 typewell GR을 sequence로 맞춥니다. |
| Self-correlation | well 내부 GR pattern consistency를 봅니다. |
| Formation planes | structural X/Y/Z prior입니다. |
| Dense ANCC proxy | formation geometry에 대한 안전한 spatial 대리 신호입니다. |
| PF | likelihood와 motion constraint를 갖는 sequential state tracking입니다. |
| Trajectory | borehole geometry와 smoothness prior입니다. |
stack은 estimator마다 편향의 패턴이 다르다는 점을 활용합니다.
| Estimator | 흔한 bias |
|---|---|
| Hold | drifting well을 underfit합니다. |
| PF | likelihood가 약하면 lag가 생길 수 있습니다. |
| Beam | plausible하지만 잘못된 GR motif로 jump할 수 있습니다. |
| DTW | 반복 pattern을 과도하게 warp할 수 있습니다. |
| Formation plane | local well offset을 놓칠 수 있습니다. |
| Dense spatial proxy | fold 안에서 안전하게 만들지 않으면 nearby geometry를 overfit할 수 있습니다. |
| GBDT residual | reliability feature가 약하면 over-correct할 수 있습니다. |
비교 feature는 다음과 같습니다.
1
2
3
4
5
6
7
8
pf_minus_hold
beam_minus_pf
dtw_minus_formation
prefix_corr
hidden_gr_missing_rate
hidden_z_span
same_well_available
path_spread
이 값들은 어떤 상황에서 어떤 경로를 더 믿어야 하는지 알려줍니다.
1
2
3
4
5
6
7
8
if prefix typewell correlation is high and GR gaps are short:
trust alignment paths more
if hidden GR is sparse and formation residual is stable:
trust formation and hold more
if same-well contact exists:
공개 겹침 활용 경로를 허용하되, 따로 추적 가능하게 둔다
post-processing은 장식이 아닙니다. 지질적 연속성을 보존하기 위한 제약입니다.
| Postprocess | 목적 |
|---|---|
| Shrinkage | 약한 evidence에 과민반응하지 않게 합니다. |
| Fade-in | 알려진 앞부분 직후 급격히 움직이지 않게 합니다. |
| Slope clipping | 관측된 tail smoothness를 존중합니다. |
| Smoothing | 고립된 row-level jump를 제거합니다. |
| Schema guard | Kaggle 제출 schema를 보존합니다. |
최종 제출은 다음 조건을 만족해야 합니다.
1
2
3
4
rows == len(sample_submission)
columns == ["id", "tvt"]
id order == sample_submission id order
all tvt finite
row order가 틀리면 지질적으로 그럴듯한 곡선도 완전히 잘못된 제출이 되고 맙니다. 각 id는 특정 well의 특정 row index에 대응하기 때문입니다.
13. 공개 점수와 비공개 점수를 나누어 읽기
여기서 제출 모드는 단순한 실행 옵션이 아니라 위험을 선택하는 장치입니다.
| 모드 | 공개 점수에서의 성격 | 비공개 점수에서의 성격 |
|---|---|---|
| Same-well physical enabled | train/test overlap을 활용할 수 있습니다 | private에서 overlap이 사라지면 위험합니다 |
| PF/beam only | public overlap 의존도가 낮습니다 | 처음 보는 well에 더 견고합니다 |
| Strict features | drilling-time causality에 가깝습니다 | batch covariate를 덜 사용할 수 있습니다 |
| Offline target-free features | 제공된 전체 covariate path를 사용합니다 | hidden TVT나 fold leakage가 없으면 안전합니다 |
| Model-package sidecar | learned correction을 추가할 수 있습니다 | 재현 가능한 inference package가 필요합니다 |
same-well contact로 얻은 강한 공개 점수가 곧바로 geology model의 강함을 증명하지는 않습니다. 정답값을 보지 않는 PF/beam/formation feature의 GroupKFold score가 private 일반화에는 더 많은 정보를 줄 수 있습니다.
| 후보 유형 | 강점 | 위험 |
|---|---|---|
| Public-aggressive overlap | public에서 보이는 same-well structure를 날카롭게 잡을 수 있습니다 | private split에서 overlap advantage가 사라질 수 있습니다 |
| Target-free PF/beam | 처음 보는 well로 일반화하기 쉽습니다 | public에만 있는 특수 구조를 덜 쓸 수 있습니다 |
| Full offline stack | 제공된 covariate geometry와 GR을 모두 사용합니다 | 구성 요소가 많아지고 validation 부담이 커집니다 |
| Sidecar-gated model package | movement control 아래 learned correction을 추가합니다 | 재현 가능한 inference package에 의존합니다 |
공개 점수, 비공개 점수, GroupKFold 점수, same-well 경로는 서로 같은 숫자가 아닙니다. 각각 다른 성격의 성능을 측정합니다.
1
2
3
4
5
6
7
8
9
10
11
public score:
visible test distribution에서의 성능을 봅니다
private score:
hidden test distribution에서의 성능을 봅니다
GroupKFold:
train well을 이용해 처음 보는 well에서의 동작을 추정합니다
same-well branch:
matching well이 있을 때 overlap 활용 효과를 봅니다
14. 핵심 정리
이 문제는 평범한 row-wise regression이 아니라 지층 경로 복원 문제입니다.
| 원칙 | 결과 |
|---|---|
| last known TVT에서 residual을 예측합니다 | flat well에서 anchor가 강하게 유지됩니다. |
TVT + Z를 formation-relative coordinate로 봅니다 | geometry와 formation surface가 물리적 의미를 갖습니다. |
| GR을 바코드처럼 다룹니다 | typewell 대비가 target-free trajectory estimator가 됩니다. |
| strict, offline, public-aggressive feature를 분리합니다 | 데이터 누수 risk가 계속 보입니다. |
| row가 아니라 well 단위로 검증합니다 | same-well autocorrelation이 CV를 부풀리지 않습니다. |
| disagreement를 uncertainty로 사용합니다 | PF, beam, hold, formation, sidecar estimate를 gate할 수 있습니다. |
| OOF evidence만 믿지 않고 inference package를 만듭니다 | test prediction이 covariate에서 재현 가능해야 합니다. |
최종 예측은 여러 물리적 추정과 잔차 모델의 통제된 결합입니다.
1
2
3
4
5
6
prefix anchor
+ target-free PF / beam / DTW / formation paths
+ well-specific GR calibration
+ residual GBDT correction
+ optional gated model-package sidecar
+ geological post-processing
하나의 feature가 전체 문제를 해결하지 않습니다. 지질 해석, 데이터 누수 통제, 제출 형식 검증이 처음부터 끝까지 함께 맞물려야 예측이 일관성을 유지합니다.