PG S6E6: 적색편이와 색지수로 풀어내는 천체 분류 — OOF Artifact 블렌딩까지
PG S6E6: 적색편이와 색지수로 풀어내는 천체 분류 — OOF Artifact 블렌딩까지
대회 링크:
Playground Series S6E6
Kaggle 코드:
PG S6E6 EDA + GBDT Bases + Artifact Blend

이 문제는 GALAXY, QSO, STAR 세 클래스를 맞히는 분류 문제입니다. 겉으로는 최종 라벨을 바로 맞히는 평범한 분류처럼 보이지만, 실제로 중요한 것은 확률을 어떻게 만들고, 그 확률을 어떤 기준으로 최종 라벨로 바꾸느냐입니다.
대상 클래스는 다음 세 가지입니다.
1
GALAXY / QSO / STAR
평가 지표는 일반 accuracy가 아니라 balanced accuracy입니다. 따라서 핵심 질문은 다음이 아닙니다.
전체 행 중 몇 개를 맞혔는가?
더 중요한 질문은 이것입니다.
GALAXY,QSO,STAR각각의 recall을 얼마나 균형 있게 지켰는가?
이 차이가 EDA, 피처 엔지니어링, fold 설계, 외부 아티팩트 검증, 블렌딩 탐색, 최종 클래스별 보정 계수까지 전부 결정합니다.
전체 흐름은 다음 순서로 보는 게 자연스럽습니다.
1
2
3
4
5
평가지표
-> 피처의 물리적 의미
-> OOF 검증
-> 확률 분포의 형태
-> 보정된 최종 라벨 결정
선택한 blend의 성능 요약입니다.
| 항목 | 값 |
|---|---|
| 가장 좋은 단일 OOF BA | 0.968129 |
| 선택된 블렌딩 OOF BA | 0.969191 |
| OOF BA 개선폭 | +0.001062 |
| OOF log loss | 0.091453 |
| OOF macro-F1 | 0.952234 |
개선폭은 작습니다. 하지만 이미 강한 단일 아티팩트 위에서 얻은 잔차 보정이기 때문에, 단순 평균으로 운 좋게 올라간 점수라기보다는 OOF 근거가 있는 미세 조정으로 읽는 게 맞습니다.
1. 지표가 먼저입니다
train의 클래스 분포는 불균형합니다.
| 클래스 | 비율 |
|---|---|
GALAXY | 0.653818 |
QSO | 0.202899 |
STAR | 0.143283 |
일반 accuracy라면 GALAXY 쪽으로 조금 치우친 모델도 꽤 좋아 보일 수 있습니다. 하지만 balanced accuracy에서는 각 클래스가 같은 비중을 갖습니다.
이 대회에서는 K = 3입니다. 즉 최종 점수는 GALAXY, QSO, STAR 각각의 recall 평균입니다.
따라서 최적화 대상은 단순한 행 단위 정답률이 아니라 클래스별 recall을 고르게 지키는 것입니다. 클래스 가중치를 둔 학습과 OOF 기반 클래스별 보정 계수 탐색은 이 지표에서 자연스럽게 나옵니다.
클래스 빈도의 역수에 가까운 가중치는 다음과 같습니다.
| 클래스 | Train 비율 | 가중치 |
|---|---|---|
GALAXY | 0.653818 | 0.509826 |
QSO | 0.202899 | 1.642856 |
STAR | 0.143283 | 2.326397 |
STAR를 틀리는 것은 단순히 드문 클래스에서 생긴 작은 잡음이 아닙니다. 공식 지표의 1/3을 차지하는 recall 손실입니다.
2. 데이터가 실제로 말해주는 것
입력 컬럼은 비교적 단순합니다.
| 피처 묶음 | 컬럼 |
|---|---|
| 하늘 좌표 | alpha, delta |
| 측광 등급 | u, g, r, i, z |
| redshift | redshift |
| 범주형 단서 | spectral_type, galaxy_population |
하지만 이 컬럼들을 모두 같은 종류의 테이블 숫자로 취급하면 신호를 놓치기 쉽습니다. 각 컬럼은 물리적으로 다른 정보를 담고 있습니다. redshift는 거리와 우주론적 효과를 강하게 반영하고, u/g/r/i/z는 서로 다른 파장대에서의 밝기이며, 범주형 컬럼은 관측 체계 안에서 이미 만들어진 강한 사전 단서에 가깝습니다.
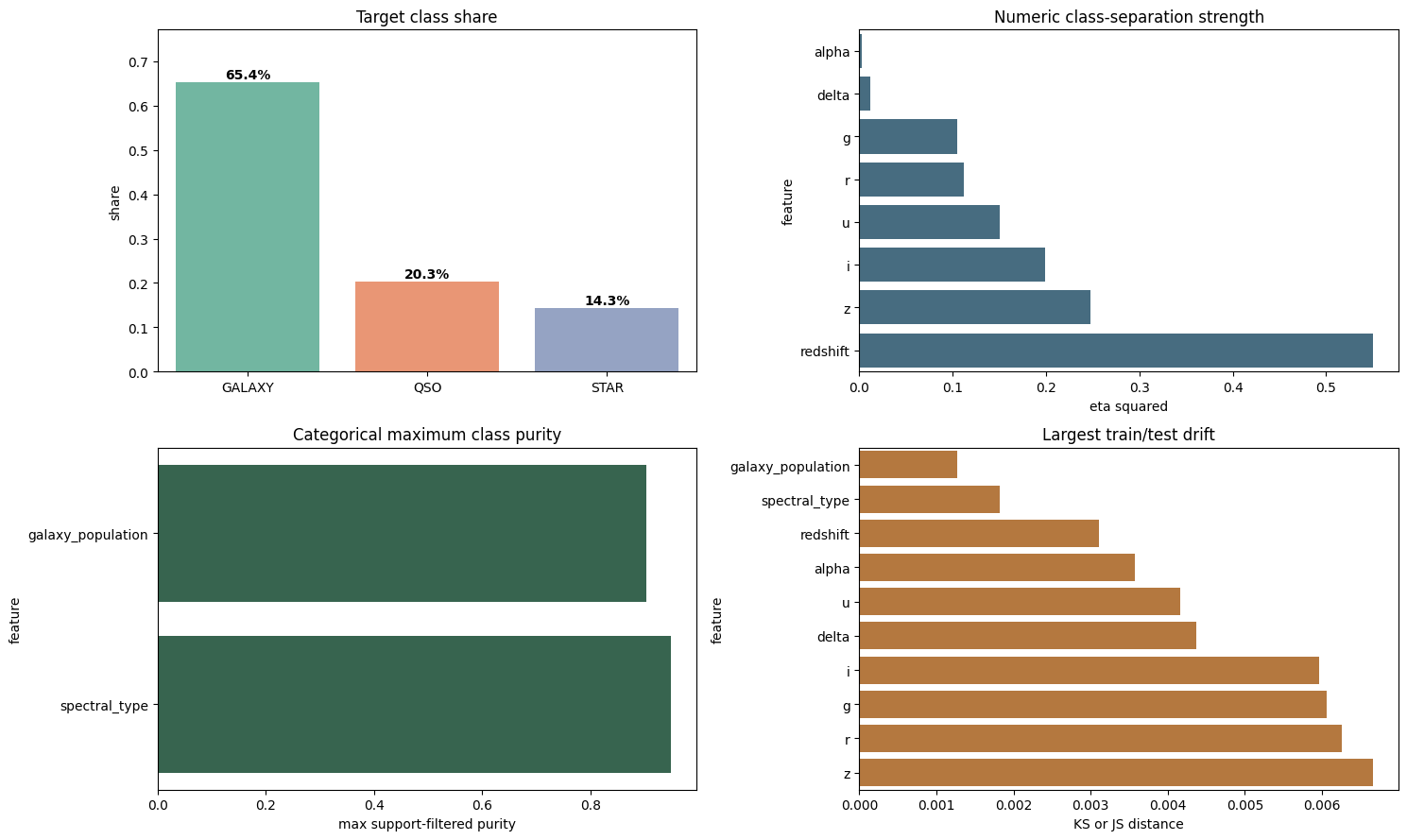
가장 먼저 보이는 신호는 redshift입니다. 효과 크기를 기준으로 보면 다음과 같습니다.
| 피처 | eta squared |
|---|---|
redshift | 0.55006 |
z | 0.24737 |
i | 0.19920 |
u | 0.15091 |
r | 0.11217 |
g | 0.10464 |
eta squared는 다음처럼 읽을 수 있습니다.
\[\eta^2 = \frac{\text{between-class variation}} {\text{total variation}}\]즉 redshift는 단순히 정답 클래스와 상관이 있는 변수가 아니라, 클래스 사이 변동을 상당히 많이 설명하는 축입니다.
두 번째 신호는 범주형 컬럼의 순도입니다. 표본 수가 충분한 그룹만 추려 보면 spectral_type의 최대 class purity는 0.94956 수준이고, galaxy_population도 0.90285까지 올라갑니다.
이 값들이 범주형 변수만으로 문제가 끝난다는 뜻은 아닙니다. 대신 트리 모델이 범주형 분기를 충분히 활용해야 하고, 범주형 단서와 redshift/측광 피처의 상호작용을 보존해야 한다는 뜻입니다.
3. 적색편이는 강한 분리 축이지만 완전한 규칙은 아닙니다
redshift 분포를 보면 어디가 쉬운 구간이고 어디가 애매한 구간인지 드러납니다.
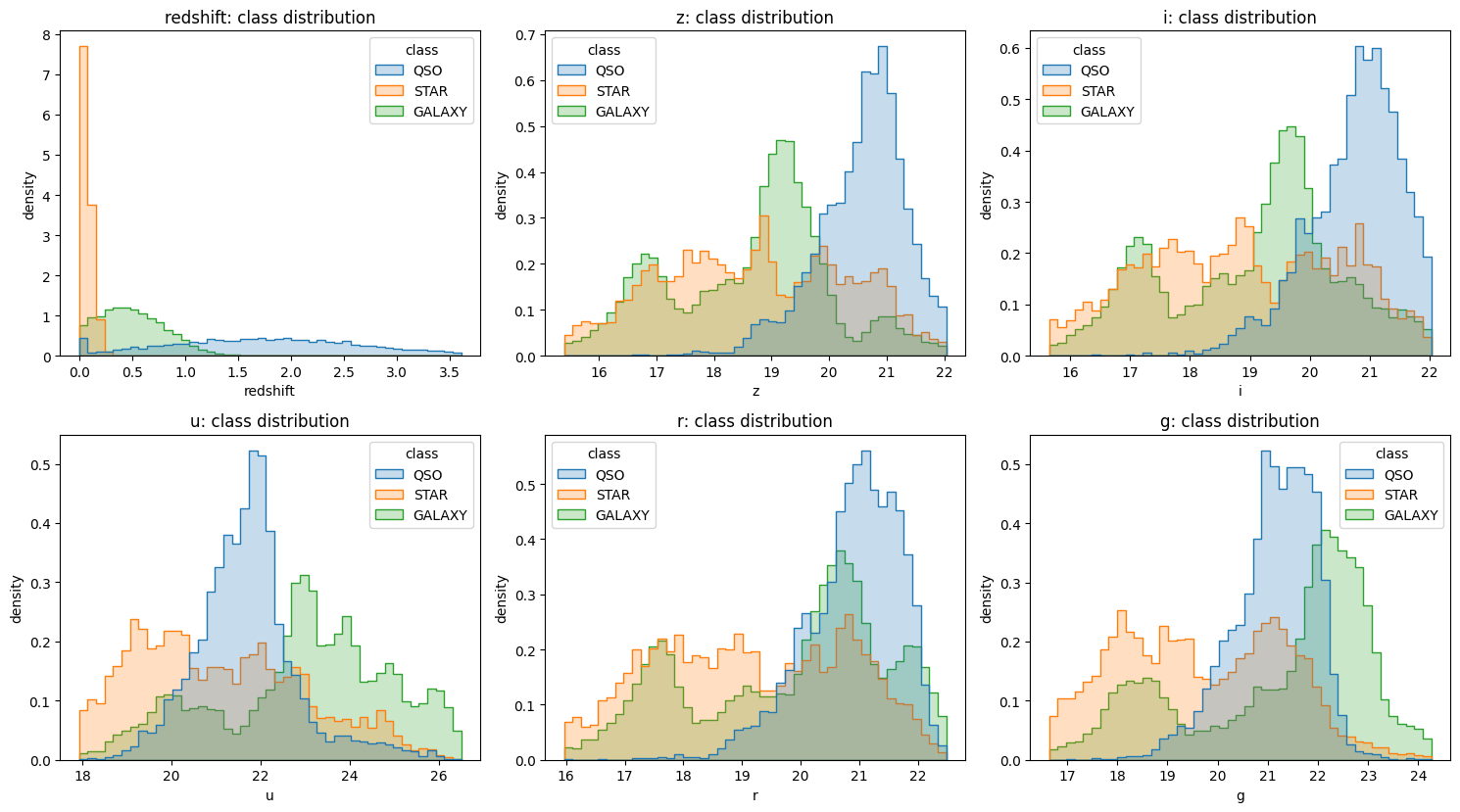
클래스별 redshift 중앙값은 다음과 같습니다.
| 클래스 | redshift 중앙값 |
|---|---|
STAR | 0.05649 |
GALAXY | 0.48196 |
QSO | 1.79889 |
직관은 꽤 분명합니다.
1
2
3
STAR -> near-zero redshift
GALAXY -> moderate redshift
QSO -> often high redshift
하지만 이게 그대로 적용되는 규칙은 아닙니다. 낮은 redshift 근처에서는 클래스가 겹치고, magnitude 분포도 넓게 포개집니다. 바로 이 애매한 영역에서 확률 모델의 역할이 커집니다.
예를 들어 다음처럼 거친 규칙을 만들 수는 있습니다.
\[\hat{y} = \begin{cases} \text{STAR}, & z_{\text{redshift}} < \tau_1 \\ \text{QSO}, & z_{\text{redshift}} > \tau_2 \\ \text{GALAXY}, & \text{otherwise} \end{cases}\]이 규칙은 물리 구조의 일부를 잡아내지만, 섞인 영역에서는 무너집니다. redshift는 하나의 절대 규칙으로 쓰기보다, 더 넓은 피처 공간 안의 강력한 축으로 두는 편이 자연스럽습니다.
4. 측광 등급은 색지수로 풀어야 합니다
u, g, r, i, z는 서로 다른 파장대의 magnitude입니다. 천문학에서 magnitude는 로그 스케일이라, 원래 등급값끼리의 단순 비교보다 magnitude 차이, 즉 색지수가 훨씬 직접적인 의미를 갖습니다.
색지수는 다음처럼 정의합니다.
\[\operatorname{color}_{a,b} = m_a - m_b\]천문학적 magnitude와 flux의 관계는 대략 다음과 같습니다.
\[m \propto -2.5\log_{10}(F)\]따라서 magnitude 차이는 flux ratio와 연결됩니다.
\[\frac{F_a}{F_b} = 10^{-0.4(m_a - m_b)}\]그래서 피처에는 두 종류를 모두 넣습니다.
1
2
u_minus_g, g_minus_r, r_minus_i, i_minus_z, ...
flux_ratio_u_g, flux_ratio_g_r, ...
이건 피처를 장식적으로 늘리는 작업이 아닙니다. 파장대별 밝기를 천체의 스펙트럼 형태로 바꾸는 과정입니다.
median color heatmap을 보면 이 차이가 잘 드러납니다.
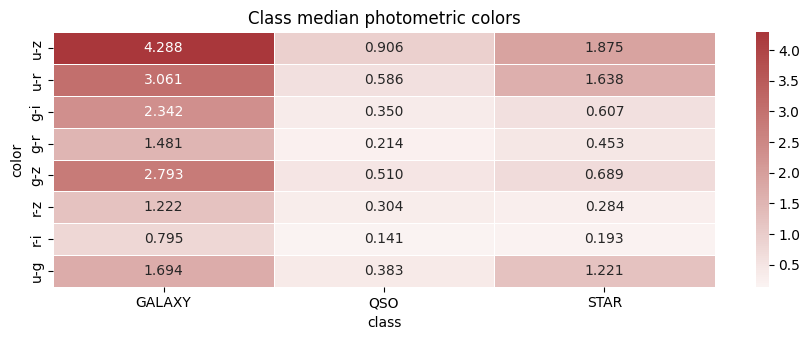
예를 들면 다음과 같습니다.
| Color | GALAXY | QSO | STAR |
|---|---|---|---|
u-z | 4.288 | 0.906 | 1.875 |
u-r | 3.061 | 0.586 | 1.638 |
g-i | 2.342 | 0.350 | 0.607 |
g-r | 1.481 | 0.214 | 0.453 |
GALAXY는 넓은 색지수에서 훨씬 붉게 나타납니다. QSO는 상대적으로 더 평평하고, STAR는 일부 색에서 중간에 놓이며 다른 클래스와 많이 겹칩니다.
따라서 단일 피처가 아니라 서로 연결된 피처 묶음이 필요합니다.
| 피처 묶음 | 역할 |
|---|---|
| color differences | spectral slope와 class separation을 잡습니다. |
| flux ratios | 같은 색 관계를 multiplicative scale로 표현합니다. |
| magnitude summaries | 전체 밝기와 모양을 요약합니다. |
| redshift interactions | 색의 의미가 redshift에 따라 달라지도록 합니다. |
redshift와 u-z scatter를 보면 interaction이 필요한 이유가 분명해집니다.
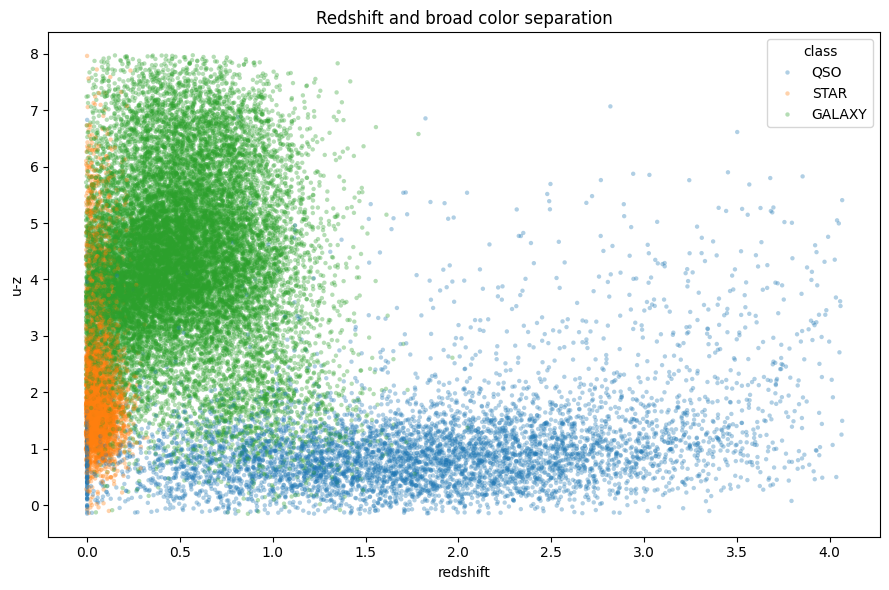
클래스별 영역은 보이지만 모든 곳에서 선형으로 갈라지지는 않습니다. 의미 있는 축이 여러 개이고, 비선형 임계값과 국소적인 상호작용이 필요한 상황입니다. 이런 구조는 GBDT가 잘 다루는 형태입니다.
코드: 색지수와 flux-ratio 피처
1
2
3
4
5
6
7
8
9
10
11
12
13
color_pairs = [
("u", "g"), ("g", "r"), ("r", "i"), ("i", "z"),
("u", "r"), ("u", "i"), ("u", "z"),
("g", "i"), ("g", "z"), ("r", "z"),
]
for a, b in color_pairs:
color = out[a] - out[b]
out[f"{a}_minus_{b}"] = color
out[f"{a}_div_{b}"] = safe_divide(out[a], out[b])
out[f"flux_ratio_{a}_{b}"] = np.power(
10.0, -0.4 * color.clip(-50, 50)
).astype("float32")
5. 적색편이를 여러 형태로 확장하는 이유
redshift는 원래 값만 봐도 효과 크기가 가장 강합니다. 그렇다고 하나의 실수형 피처로만 두면, 트리 모델이나 신경망 계열 아티팩트가 활용하기에 다소 제한될 수 있습니다. 그래서 여러 형태로 확장합니다.
| 피처 | 역할 |
|---|---|
redshift_abs | 음수 또는 near-zero behavior를 대칭적으로 다룹니다. |
redshift_sq | high-redshift regime을 강조합니다. |
redshift_log1p | 긴 오른쪽 꼬리를 압축합니다. |
redshift_signed_log1p | 부호를 보존하면서 scale을 압축합니다. |
near_zero_redshift | 항성 또는 가까운 천체 후보를 표시합니다. |
high_redshift | quasar-like regime을 표시합니다. |
very_high_redshift | extreme QSO-like case를 분리합니다. |
개념적으로는 기저 확장입니다.
\[x \rightarrow \phi(x) = \left[ x,\ |x|,\ x^2,\ \log(1+x_+),\ \mathbf{1}(|x|<0.1),\ \mathbf{1}(x>1),\ \mathbf{1}(x>2) \right]\]이렇게 하면 모델 종류마다 같은 물리 정보를 다른 방식으로 쓸 수 있습니다. 트리는 high_redshift에서 바로 분기하고, 신경망 계열 아티팩트는 부드럽게 변환된 값을 활용하며, 블렌딩은 이 둘을 모두 이용할 수 있습니다.
redshift와 색지수의 상호작용도 중요합니다.
같은 색 차이라도 적색편이 구간에 따라 의미하는 클래스가 달라질 수 있기 때문입니다.
6. 천문 데이터의 구조를 읽는 EDA
천문 데이터 EDA는 어느 피처가 강한지 확인하는 것으로 끝나지 않습니다. 관측값이 어떻게 만들어졌는지, 클래스 경계가 어디서 휘고 겹치는지, 어떤 피처는 정답 규칙이 아니라 사전 단서로만 다루어야 하는지를 함께 봐야 합니다.
범주형 변수와 클래스의 결합 정도는 Cramer’s V로 요약할 수 있습니다.
여기서 r, c는 분할표의 차원입니다. 두 범주형 컬럼은 꽤 강한 신호를 갖습니다.
| 피처 | 클래스와의 Cramer’s V | 의미 |
|---|---|---|
galaxy_population | 0.59349 | 집단 구분이 주는 강한 사전 단서 |
spectral_type | 0.52480 | 스펙트럼 구분이 주는 강한 사전 단서 |
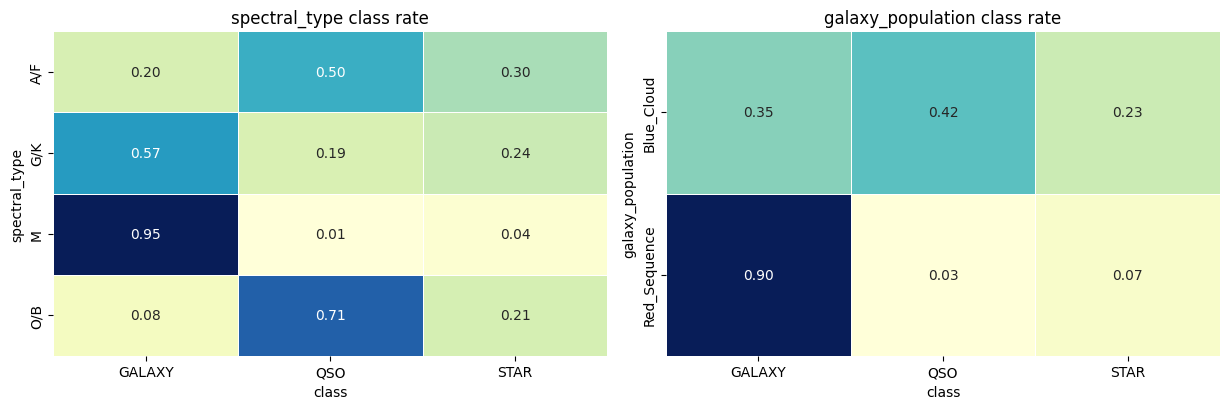
히트맵을 보면 M은 거의 GALAXY이고, O/B는 QSO 쪽으로 강하게 치우칩니다. Red_Sequence도 대부분 GALAXY입니다. 하지만 Blue_Cloud처럼 섞인 그룹도 있고, 여러 스펙트럼 그룹에 소수 클래스가 남아 있습니다. 따라서 범주형 컬럼은 정답을 직접 알려주는 라벨이 아니라, 질 좋은 사전 단서로 다루는 편이 맞습니다.
색-색 평면도 같은 이야기를 보여줍니다.
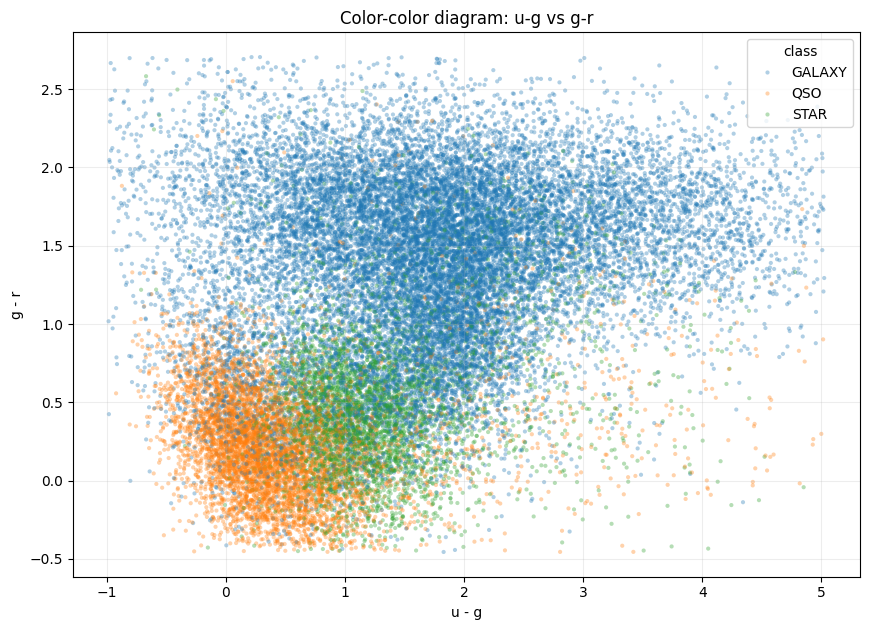
두 축은 인접한 파장대 사이의 스펙트럼 기울기를 근사합니다.
\[\Delta_{ug}=u-g, \qquad \Delta_{gr}=g-r\]QSO는 낮은 g-r 구간에 많이 놓이고, GALAXY는 더 높은 g-r 영역에 덩어리를 형성합니다. STAR는 중간에서 양쪽과 겹칩니다. 이 겹침 때문에 색지수는 강력한 신호이지만, 하나의 축 기준 규칙으로 끝낼 수는 없습니다.
redshift ECDF는 임계값이 필요한 구간을 더 분명하게 보여줍니다.
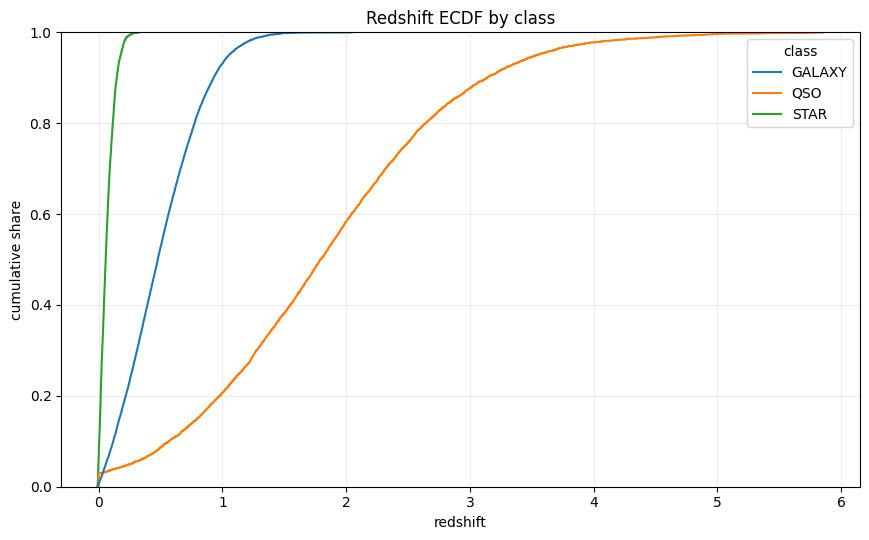
클래스 c의 ECDF는 다음과 같습니다.
STAR는 0에 가까운 redshift에서 빠르게 누적되고, GALAXY는 중간 영역을 차지하며, QSO는 높은 redshift 쪽 꼬리를 길게 유지합니다. near_zero_redshift, high_redshift, very_high_redshift 같은 flag는 임의로 만든 bin이 아니라 클래스별 분포에서 의미가 갈리는 구간을 표시합니다.
train/test와 original reference의 ECDF를 비교하면, 어떤 데이터를 얼마나 믿어야 하는지도 보입니다.
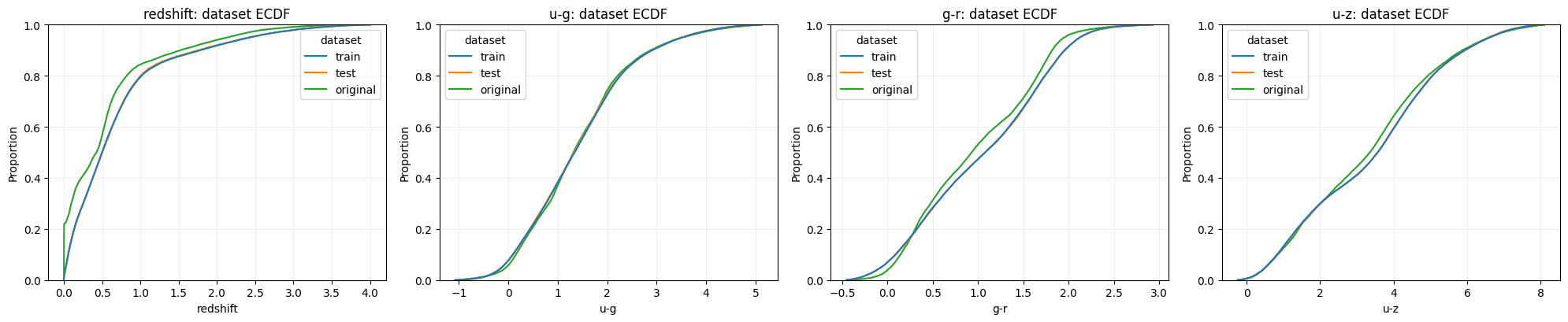
대회 train/test는 redshift, u-g, g-r, u-z에서 거의 겹칩니다. 반면 원본 참조 데이터는 redshift와 일부 측광 꼬리 영역에서 차이가 큽니다. 원본 u, g, z에는 -9999 sentinel도 보입니다. 따라서 원본 데이터는 물리적 직관을 얻는 데는 유용하지만, 그대로 검증 기준으로 삼기에는 위험합니다.
alpha, delta는 단순한 독립 숫자가 아니라 하늘 위의 위치 구조로 다루어야 합니다.
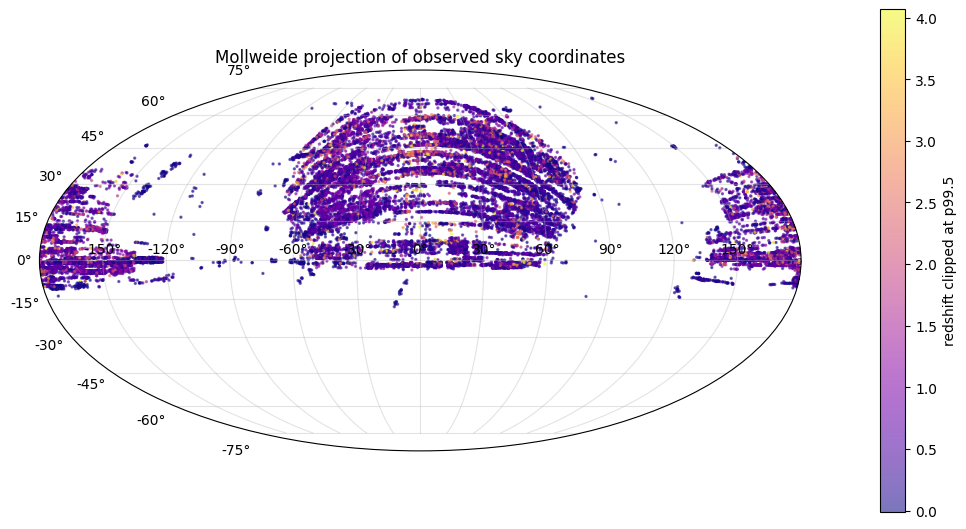
투영 그림은 균일한 구면 표본이 아니라 실제 관측이 이루어진 하늘 영역을 보여줍니다. 또한 적경은 0°/360°에서 이어집니다. 각도를 원래 숫자 그대로만 쓰기보다, 주기성을 반영한 인코딩과 구면 좌표를 함께 쓰는 편이 안전합니다.
코드: 하늘 좌표와 범주형 조합
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
alpha_rad = np.deg2rad(out["alpha"])
delta_rad = np.deg2rad(out["delta"])
out["alpha_sin"] = np.sin(alpha_rad).astype("float32")
out["alpha_cos"] = np.cos(alpha_rad).astype("float32")
out["delta_sin"] = np.sin(delta_rad).astype("float32")
out["delta_cos"] = np.cos(delta_rad).astype("float32")
out["sky_x"] = out["delta_cos"] * out["alpha_cos"]
out["sky_y"] = out["delta_cos"] * out["alpha_sin"]
out["sky_z"] = out["delta_sin"]
out["spectral_population"] = (
out["spectral_type"].astype(str)
+ "__"
+ out["galaxy_population"].astype(str)
)
out["spectral_highz"] = (
out["spectral_type"].astype(str)
+ "__highz_"
+ out["high_redshift"].astype(str)
)
정리하면 다음과 같습니다.
| EDA에서 보이는 구조 | 피처 설계로 이어지는 점 |
|---|---|
| 범주형 컬럼별 클래스 비율 | 범주형 피처와 범주형 조합을 유지합니다. |
| 색-색 평면의 겹침 | 여러 색지수와 flux-ratio 변환을 사용합니다. |
클래스별 redshift ECDF | redshift 기저 확장과 threshold flag를 추가합니다. |
| train/test ECDF의 정렬 | 원본 참조 데이터보다 대회 OOF를 더 신뢰합니다. |
| 하늘 좌표의 관측 영역 | 각도의 주기성을 반영하고 구면 좌표를 추가합니다. |
7. 분포 이동 점검은 신뢰도 문제입니다
분포 이동 점검은 “분포가 완전히 같은가?”를 확인하는 것이 아닙니다. OOF에서 본 행과 test 행이 얼마나 같은 분포에서 왔는지를 보는 과정입니다.
train/test 사이의 가장 큰 분포 차이는 작습니다.
| 피처 | Drift statistic |
|---|---|
z | 0.00666 |
r | 0.00626 |
g | 0.00606 |
i | 0.00596 |
redshift | 0.00311 |
수치형 피처에는 KS 방식의 분포 거리 측정을 사용합니다.
\[D_{KS} = \sup_x \left| F_{\text{train}}(x) - F_{\text{test}}(x) \right|\]범주형 피처에는 Jensen-Shannon distance를 사용합니다.
여기서 결론은 “분포 이동이 전혀 없다”가 아닙니다. 더 좁게 말하면, 대회 train/test split의 단일 피처 분포에서는 큰 drift가 보이지 않는다는 뜻입니다. 이것이 대회 fold로 만든 OOF와 그에 맞춘 아티팩트를 신뢰할 수 있는 근거가 됩니다.
반면 원본 SDSS17 참조 데이터는 다릅니다. 클래스 비율이 다르고, 대회 train과의 redshift KS도 훨씬 큽니다.
| 비교 | 신호 |
|---|---|
원본 STAR 비율 - 대회 train STAR 비율 | +0.07266 |
원본과 대회 데이터의 redshift KS | 0.19553 |
원본 참조 데이터는 피처에 대한 직관을 얻는 데는 도움이 됩니다. 하지만 검증 기준을 슬그머니 원본 데이터 쪽으로 바꾸면 위험합니다.
8. OOF가 있어야 믿을 수 있습니다
확률 파일은 OOF에서 검증되기 전까지 서로 바꿔 쓸 수 없습니다.
행 i의 OOF 예측은 다음과 같이 정의됩니다.
여기서 k_i는 행 i가 속한 validation fold이고, f_{-k_i}는 그 fold를 제외하고 학습한 모델입니다.
in-sample prediction은 이미 본 행을 얼마나 잘 설명하는지 묻습니다. OOF prediction은 같은 train 분포에서 나온 처음 보는 행에 대해 모델링 절차가 얼마나 잘 작동하는지 묻습니다.
OOF의 역할은 네 가지입니다.
| OOF의 역할 | 의미 |
|---|---|
| 새 GBDT base 평가 | train 행 누수 없이 각 모델이 지표에 기여하는 정도를 봅니다. |
| 외부 아티팩트 검증 | 외부 확률 파일의 행/클래스 순서가 맞는지 확인합니다. |
| 상관 기반 가지치기 | OOF 확률의 모양으로 멤버 간 중복을 봅니다. |
| 블렌딩 가중치 탐색 | 대회 지표 기준으로 가중치를 찾습니다. |
아티팩트를 불러오는 건 단순한 파일 관리가 아닙니다. 이름이 그럴듯하거나 public score가 좋다고 믿는 게 아니라, 호환되는 OOF 확률 행렬과 그에 대응하는 test 확률 행렬을 제공할 때만 신뢰할 수 있습니다.
9. 새 GBDT 모델은 내부 기준점입니다
CatBoost, LightGBM, XGBoost는 엔지니어링한 피처 테이블 위에서 학습됩니다. OOF score는 이미 강합니다.
| Model | OOF BA | OOF Log Loss |
|---|---|---|
public_xgboost | 0.965352 | 0.098110 |
public_catboost | 0.964304 | 0.112588 |
public_lightgbm | 0.964266 | 0.095724 |
이 모델들이 최종 결과를 주도하는 건 아닙니다. 하지만 역할은 분명합니다.
- 피처 엔지니어링이 실제로 예측력을 갖는지 확인합니다.
- 재현 가능한 새 OOF/test 확률 멤버를 제공합니다.
- 신경망 계열 아티팩트 중심의 후보군에 트리 모델의 결정 경계를 추가합니다.
강한 신경망 계열 아티팩트가 새 GBDT보다 뛰어나더라도, GBDT는 서로 다른 위치에서 오류를 냅니다. 그래서 최종 블렌딩에서 0이 아닌 가중치를 받을 여지가 생깁니다.
코드: fold-safe GBDT 확률 생성
1
2
3
4
5
6
7
8
9
10
11
12
for fold in range(N_FOLDS):
trn_idx = np.where(fold_id != fold)[0]
val_idx = np.where(fold_id == fold)[0]
model.fit(X_train.iloc[trn_idx], y[trn_idx])
oof[val_idx] = normalize_probs(
model.predict_proba(X_train.iloc[val_idx])
)
test_probs += normalize_probs(
model.predict_proba(X_test)
) / N_FOLDS
test 예측도 같은 fold 절차에 맞춥니다.
\[\hat{p}^{\text{test}} = \frac{1}{K} \sum_{k=1}^{K} f_{-k}(x_{\text{test}})\]10. 아티팩트 블렌딩은 2차 모델입니다
가장 강한 단일 멤버는 다음입니다.
| 멤버 | 출처 | OOF BA |
|---|---|---|
realmlp_pytorch_5fold_6epoch | 첨부 아티팩트 | 0.968129 |
선택된 블렌딩은 이것을 대체하려는 것이 아니라 보정하려는 것입니다.
멤버 m의 확률 벡터를 p_m(x)라고 하면 확률 블렌딩은 다음과 같습니다.
최종 가중치를 보면 방향이 잘 드러납니다.
| 멤버 | 가중치 |
|---|---|
realmlp_pytorch_5fold_6epoch | 0.62239 |
public_lightgbm | 0.18710 |
realmlp_seed2026_full_fullrows_fullorig_5fold | 0.05725 |
public_catboost | 0.05381 |
| high-score stack 아티팩트 | 0.03036 |
| RealMLP full 아티팩트 | 0.02729 |
public_xgboost | 0.02071 |
| Cat 아티팩트 | 0.00110 |
이것은 모든 모델을 비슷하게 믿는 평균이 아닙니다. 가장 강한 아티팩트가 대부분의 가중치를 갖고, GBDT와 다른 아티팩트는 구조적인 잔차 보정 역할을 합니다.
그래서 개선폭이 작아도 해석은 분명합니다. 이미 강한 멤버가 있는 후보군에서는 모두 평균낸다고 성능이 오르지 않습니다. 다른 모델이 서로 다르게 틀리는 지점을 찾아 클래스별 recall을 조금 개선하는 게 핵심입니다.
11. 상관 기반 가지치기는 가짜 다양성을 줄입니다
점수가 좋아도 OOF correlation이 매우 높은 아티팩트가 많습니다. 같은 redshift, 색지수, 범주형 신호에서 비슷한 클래스 경계를 학습하기 때문입니다.
상관 기반 가지치기는 다음 값을 봅니다.
\[\rho_{ij} = \operatorname{corr} \left( \operatorname{vec}(P_i^{OOF}), \operatorname{vec}(P_j^{OOF}) \right)\]이미 선택된 멤버와 OOF 확률이 거의 같은 저점수 멤버는 블렌딩 탐색에 잡음만 더할 뿐입니다.
남겨둔 후보군 안에서도 correlation은 높습니다.
| Pair | OOF Corr | Disagreement |
|---|---|---|
| RealMLP PyTorch vs public XGBoost | 0.990921 | 0.018535 |
| RealMLP PyTorch vs public CatBoost | 0.988360 | 0.022361 |
| RealMLP PyTorch vs public LightGBM | 0.989980 | 0.019027 |
| RealMLP PyTorch vs high-score stack | 0.985997 | 0.023951 |
이 정도면 블렌딩은 공격적으로 움직이기보다 보수적으로 움직여야 합니다.
다양성은 모델 이름이 다른 데서 나오지 않습니다. OOF에서 틀리는 방식이 얼마나 다른가가 더 중요합니다.
12. 클래스별 보정 계수는 지표에 맞춘 결정 규칙입니다
선택된 블렌딩의 확률이 곧 최종 라벨은 아닙니다. balanced accuracy에서는 클래스별 보정 계수로 결정 경계를 조정할 수 있습니다.
\[\hat{y} = \arg\max_c \left[ \lambda_c p_c(x) \right]\]선택된 보정 계수는 다음과 같습니다.
| 클래스 | 보정 계수 |
|---|---|
GALAXY | 0.770524 |
QSO | 1.020000 |
STAR | 1.275000 |
GALAXY는 다수 클래스이므로 확률을 조금 깎습니다. STAR는 가장 작은 클래스이므로 결정 단계에서 조금 더 밀어줍니다.
이건 STAR가 실제로 더 흔하다고 가정하는 게 아닙니다. 확률 추정과 지표에 맞춘 최종 라벨 결정을 분리하는 겁니다.
이것은 클래스 확률 추정값입니다.
하지만 최종 라벨은 다음 규칙으로 정합니다.
\[\arg\max_c \lambda_c p(y=c \mid x)\]이 규칙이 목표 지표에 맞춰 최종 라벨을 고릅니다.
최종 제출의 클래스 비율도 이 방향을 반영합니다.
| 클래스 | Train 비율 | 제출 비율 |
|---|---|---|
GALAXY | 0.653818 | 0.632223 |
QSO | 0.202899 | 0.208047 |
STAR | 0.143283 | 0.159731 |
이건 임의의 조작이 아니라 클래스별 recall을 균형 있게 맞춘 결과입니다.
13. 제출 파일보다 확률 아티팩트가 중요합니다
재사용 가능한 아티팩트는 다음 묶음입니다.
1
OOF 확률 + test 확률 + manifest + 선택된 블렌딩 metadata
이 묶음은 다음 블렌딩의 멤버가 됩니다.
- 이전 아티팩트를 읽습니다.
- OOF로 검증합니다.
- 새 GBDT base와 블렌딩합니다.
- 새로 검증된 확률 아티팩트를 냅니다.
선택된 출력은 다음과 같습니다.
| 아티팩트 | 종류 | OOF BA | OOF Log Loss | OOF Macro-F1 |
|---|---|---|---|---|
eda03_gbdt_artifact_blend | selected:dirichlet_blend_22 | 0.969191 | 0.091453 | 0.952234 |
그래서 아티팩트 관리가 중요합니다. 각 run이 행 순서를 보존한 OOF/test 확률을 남기면, 다음 블렌딩이 모든 모델을 다시 돌리지 않고도 통계적으로 조합할 수 있습니다. 반대로 제출 파일만 남기면 대부분의 정보가 사라집니다.
14. 전체 논리 정리
전체 논리 흐름은 다음과 같습니다.
1
평가지표 -> 피처의 의미 -> OOF 근거 -> 확률의 형태 -> 보정된 결정 규칙
피처 쪽 근거는 변환이 왜 필요한지 설명합니다.
| 관찰 | 모델링으로 이어지는 점 |
|---|---|
redshift의 클래스 효과가 가장 큽니다. | redshift를 확장하고 색지수와의 상호작용을 만듭니다. |
| magnitude는 로그 스케일입니다. | 색지수와 flux ratio를 사용합니다. |
색-색 평면과 redshift ECDF는 클래스별로 다른 모양을 보입니다. | 하나의 임계값 규칙보다 구간별 비선형 모델이 필요합니다. |
| 하늘 좌표에는 관측 영역 구조가 있습니다. | 각도 원값만 쓰지 말고 각도 구조를 인코딩합니다. |
| 범주형 컬럼의 순도가 높습니다. | 범주형 분기와 조합 피처를 유지합니다. |
| train/test의 단일 피처 drift가 작습니다. | 원본 참조 데이터보다 대회 OOF를 더 신뢰합니다. |
| 클래스 비율이 불균형합니다. | 일반 accuracy가 아니라 balanced accuracy를 최적화합니다. |
OOF 근거는 블렌딩을 어디까지 믿을 수 있는지 설명합니다.
| OOF 근거 | 모델링으로 이어지는 점 |
|---|---|
| RealMLP 아티팩트가 가장 강한 단일 멤버입니다. | 이를 블렌딩의 중심으로 둡니다. |
| GBDT는 강하면서도 오류 형태가 조금 다릅니다. | 확률의 잔차 보정으로 사용합니다. |
| 많은 아티팩트가 지나치게 비슷합니다. | 가짜 다양성을 가지치기합니다. |
| 클래스별 보정 계수가 BA를 개선합니다. | 최종 라벨 규칙을 클래스별 recall에 맞춥니다. |
최종 blend의 개선폭은 다음과 같습니다.
\[0.969191 - 0.968129 = 0.001062\]강한 tabular baseline 위에서는 남은 개선이 대부분 작은 잔차 오류 보정에서 나옵니다. 개선폭은 작지만, 무작정 평균을 낸 결과가 아니라 OOF 근거로 뒷받침되는 개선입니다.
15. 요약
아티팩트 블렌딩은 단순히 파일을 많이 섞는 일이 아닙니다. 평가지표, 피처의 의미, fold-safe 확률 생성, OOF 정렬, 확률 상관, 지표에 맞춘 최종 라벨 결정이 모두 맞물려야 합니다.
결과 사슬은 다음과 같습니다.
1
2
3
4
적색편이와 색지수가 신호를 설명합니다.
OOF가 신뢰도를 설명합니다.
상관관계가 가지치기를 설명합니다.
클래스별 보정 계수가 최종 라벨을 설명합니다.
블렌딩 가중치는 이 사슬의 마지막 숫자 표현입니다. 그 자체가 논리를 대체하지는 않습니다.