BirdCLEF 2026: EoS9 + OOF-Gated PCEN
BirdCLEF 2026: EoS9 + OOF-Gated PCEN
Competition link:
BirdCLEF+ 2026
Kaggle notebook link:
BirdCLEF 2026: EoS9 + OOF-Gated PCEN
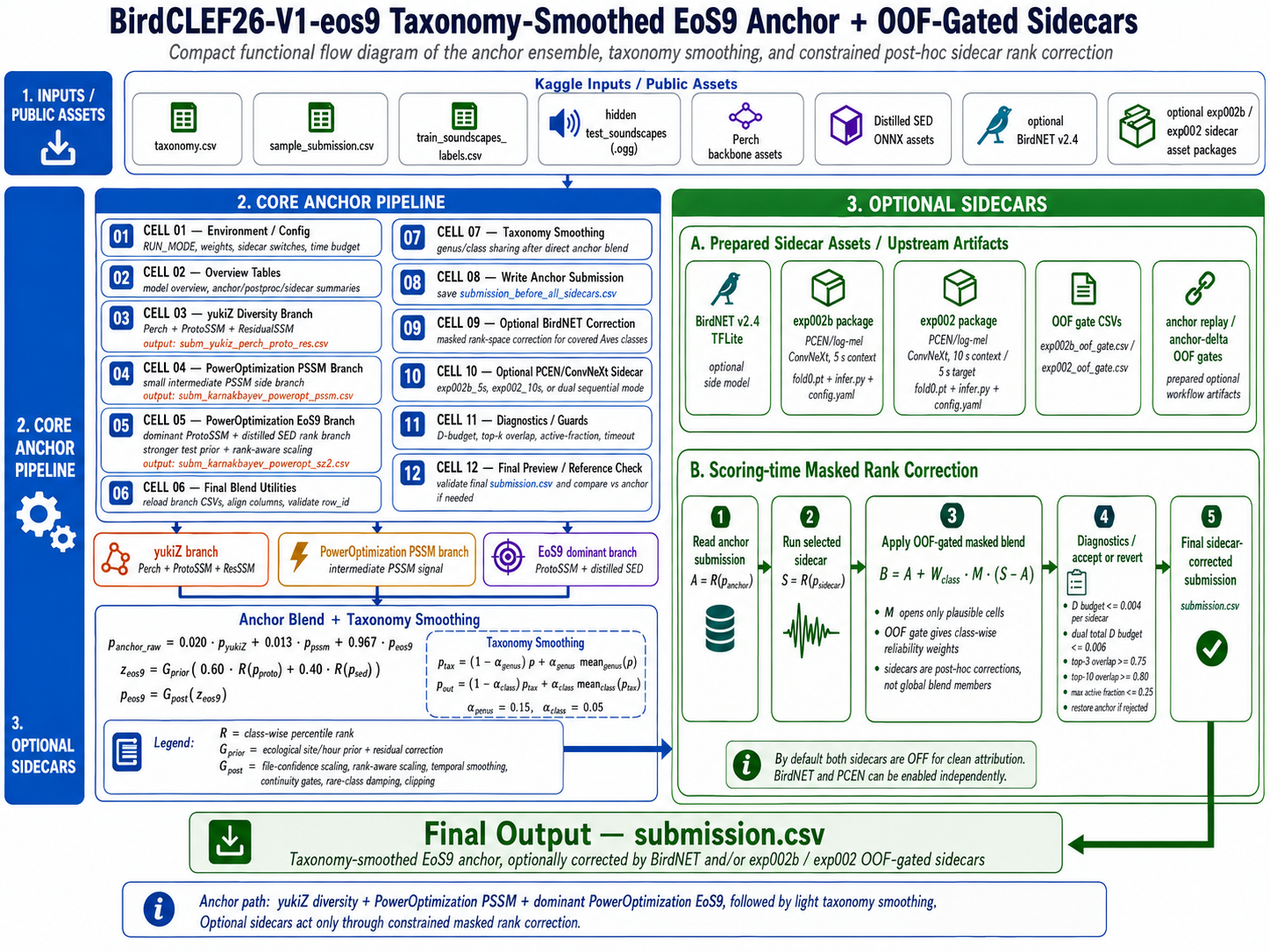
The clearest way to read this notebook is as a controlled submission architecture, not as a single-model inference script. Its purpose is not to stack as many audio classifiers as possible. The central idea is deliberately conservative:
Keep a strong public EoS9-style anchor fixed, then allow optional sidecars to move only the parts of the prediction matrix where offline evidence says they are allowed to help.
That distinction matters in BirdCLEF. The target is a large multilabel soundscape table: every row_id corresponds to a short time slice, and every class column is a species or taxon label. Small probability perturbations can change rank-sensitive leaderboard behavior, but an ungated side model can also damage classes where it has no reliable signal.
The notebook therefore separates the system into three layers:
| Layer | Role |
|---|---|
| Anchor | A public EoS9-style three-branch ensemble that produces the canonical submission. |
| Post-anchor smoothing | A light taxonomy prior that shares evidence among related labels. |
| Sidecar corrections | Optional BirdNET and PCEN/ConvNeXt rank corrections gated by masks, OOF class weights, and movement budgets. |
The active notebook configuration is:
| Component | Active Setting |
|---|---|
RUN_MODE | eos9_tax |
| Anchor weights | 0.012 yukiZ, 0.021 PowerOptimization PSSM, 0.967 PowerOptimization EoS9 |
| Main rank blend | 0.600 ProtoSSM rank + 0.400 SED rank |
| Taxonomy smoothing | genus 0.15, class 0.05 |
| BirdNET sidecar | enabled, but dry-run public rows keep anchor when row IDs cannot match |
| PCEN sidecar | enabled, exp002b_5s, fold [0], OOF gate enabled |
| Final dry-run result | 3 rows, 235 columns, finite probabilities in [0.461531, 0.529922] |
The key engineering rule is:
1
anchor first, correction second, validation always
1. Submission Pipeline
The anchor is a compact three-branch ensemble:
\[p_{\text{anchor raw}} = w_y p_{\text{yukiZ}} + w_p p_{\text{PSSM}} + w_s p_{\text{EoS9}}\]with:
\[(w_y, w_p, w_s) = (0.012,\ 0.021,\ 0.967)\]The dominant branch is the EoS9 / PowerOptimization-style branch. Inside that branch, the notebook combines ProtoSSM and distilled SED predictions in rank space:
\[z = 0.60 \cdot R(p_{\text{ProtoSSM}}) + 0.40 \cdot R(p_{\text{SED}})\]where (R(\cdot)) denotes class-wise percentile rank. The reason to blend ranks rather than raw probabilities is that the branch outputs are not necessarily calibrated on the same scale. Rank blending asks a simpler question: which classes does each branch place near the top for a given row?

After the direct blend, the notebook applies taxonomy smoothing and writes submission.csv. Only then do the optional sidecars get a chance to make local rank-space corrections. That ordering is important:
1
2
branch CSVs -> direct anchor -> taxonomy smoothing -> submission_before_all_sidecars.csv
-> optional sidecars -> final submission.csv
The sidecars are not global ensemble members. They are post-processing modules whose movement is explicitly budgeted.
2. Why The Anchor Is The Control Path
The notebook is built around the EoS9 anchor because it is already a strong, structured baseline. It contains several pieces that are hard to replace with a small side model:
| Anchor Part | Contribution |
|---|---|
| yukiZ Perch / ProtoSSM / ResidualSSM | Low-weight diversity from a pretrained Perch-based path. |
| PowerOptimization PSSM branch | A small intermediate branch saved from the Karnakbayev PowerOptimization pipeline. |
| PowerOptimization EoS9 branch | The dominant ProtoSSM + distilled SED rank branch with prior and rank-aware scaling. |
| Ecological priors | Site/hour and test-prior effects that improve plausible taxon ranking. |
| Temporal smoothing and continuity gates | Suppress single-window spikes and encourage soundscape consistency. |
| Rank-aware scaling | Gives extra structure to file-level high-confidence classes. |
The branch registry is deliberately explicit:
| Branch | Weight | Output File | Role |
|---|---|---|---|
yukiZ_Perch_ProtoSSM_ResSSM | 0.012 | subm_yukiz_perch_proto_res.csv | small pretrained diversity |
Karnakbayev_PowerOptimization_PSSM | 0.021 | subm_karnakbayev_poweropt_pssm.csv | intermediate PSSM side branch |
Karnakbayev_PowerOptimization_EoS9 | 0.967 | subm_karnakbayev_poweropt_sz2.csv | dominant EoS9 rank branch |
Show notebook snippet: front-of-notebook control weights
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
RUN_MODE = "eos9_tax"
if RUN_MODE == "eos9_tax":
YUKIZ_BLEND_WEIGHT = 0.012
POWEROPT_PSSM_BLEND_WEIGHT = 0.021
POWEROPT_SZ2_BLEND_WEIGHT = 0.967
elif RUN_MODE == "eos9_no_pssm":
YUKIZ_BLEND_WEIGHT = 0.012
POWEROPT_PSSM_BLEND_WEIGHT = 0.0
POWEROPT_SZ2_BLEND_WEIGHT = 0.988
elif RUN_MODE == "poweropt_eos9_only":
YUKIZ_BLEND_WEIGHT = 0.0
POWEROPT_PSSM_BLEND_WEIGHT = 0.0
POWEROPT_SZ2_BLEND_WEIGHT = 1.0
PROTO_RANK_WEIGHT = 0.600
SED_RANK_WEIGHT = 1.0 - PROTO_RANK_WEIGHT
assert abs(
YUKIZ_BLEND_WEIGHT
+ POWEROPT_PSSM_BLEND_WEIGHT
+ POWEROPT_SZ2_BLEND_WEIGHT
- 1.0
) < 1e-9
assert abs((PROTO_RANK_WEIGHT + SED_RANK_WEIGHT) - 1.0) < 1e-9
This pattern matters for public competition notebooks. Every score-changing knob is visible at the top, and the notebook asserts that the weight contracts still hold. That prevents silent drift across experiment runs.
3. Taxonomy Smoothing
BirdCLEF labels are not independent in the real world. Species share genus, class, habitat, and acoustic confusions. The anchor already produces a strong per-class ordering, but a small biological prior can help when two related labels are close.
The taxonomy smoothing step implements that prior directly. For a genus group (g):
\[p_c \leftarrow (1 - \alpha_g)p_c + \alpha_g \operatorname{mean}_{j \in g}(p_j)\]Then for a broader class group (k):
\[p_c \leftarrow (1 - \alpha_k)p_c + \alpha_k \operatorname{mean}_{j \in k}(p_j)\]The active values are:
\[\alpha_g = 0.15, \qquad \alpha_k = 0.05\]In the notebook dry run, taxonomy.csv produced 29 multi-species genus groups and 4 multi-label class groups.

The step is not a replacement for the acoustic model. It is a weak sharing prior:
1
2
3
preserve most of the anchor score,
borrow a little evidence from related labels,
clip and validate the same output schema.
Show notebook snippet: taxonomy smoothing
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
def f_TAX_SMOOTHING_POSTPROC(f_direct=direct, genus_alpha=None, class_alpha=None):
submission = f_direct()
genus_alpha = TAX_GENUS_ALPHA if genus_alpha is None else float(genus_alpha)
class_alpha = TAX_CLASS_ALPHA if class_alpha is None else float(class_alpha)
taxonomy_path = _find_taxonomy_path_for_smoothing()
if taxonomy_path is None:
msg = "taxonomy.csv not found; TAX_SMOOTHING cannot be applied"
if globals().get("TAX_SMOOTHING_REQUIRE", True):
raise FileNotFoundError(msg)
submission.index.name = "row_id"
return submission
tax = pd.read_csv(taxonomy_path)
species_to_genus = {}
species_to_class = {}
for _, row in tax.iterrows():
label = str(row.get("primary_label", ""))
sci = str(row.get("scientific_name", ""))
class_name = str(row.get("class_name", ""))
genus = sci.split(" ")[0] if " " in sci else sci
if label:
species_to_genus[label] = genus
species_to_class[label] = class_name
probs = submission.to_numpy(dtype=np.float32, copy=True)
for members in multi_genus.values():
idx = [col_to_idx[m] for m in members]
group_mean = probs[:, idx].mean(axis=1, keepdims=True)
probs[:, idx] = (1.0 - genus_alpha) * probs[:, idx] + genus_alpha * group_mean
for members in multi_class.values():
idx = [col_to_idx[m] for m in members]
group_mean = probs[:, idx].mean(axis=1, keepdims=True)
probs[:, idx] = (1.0 - class_alpha) * probs[:, idx] + class_alpha * group_mean
probs = np.clip(probs, 0.0, 1.0)
return pd.DataFrame(probs, index=submission.index, columns=submission.columns)
4. Sidecars Are Local Corrections, Not New Anchors
The notebook has two optional sidecar families:
| Sidecar | Active State | Intended Use |
|---|---|---|
| BirdNET v2.4 | enabled | conservative correction for covered Aves labels |
| PCEN/ConvNeXt exp002b | enabled | custom weak-audio correction gated by class-wise OOF evidence |
The shared formula is:
\[A = R(p_{\text{anchor}}), \qquad S = R(p_{\text{sidecar}})\] \[B = A + W_{\text{class}} \cdot M \cdot (S - A)\]where:
| Symbol | Meaning |
|---|---|
| (A) | anchor ranks after taxonomy smoothing |
| (S) | sidecar ranks |
| (M) | boolean cell mask where movement is allowed |
| (W_{\text{class}}) | scalar or class-wise correction weight |
| (B) | corrected rank table |
The philosophy is deliberately cautious. A sidecar is allowed to nudge the anchor, not replace it.

The correction must pass several guards:
| Guard | Purpose |
|---|---|
| Top-k mask | Move only classes already plausible under the anchor or strongly proposed by the sidecar. |
Anchor threshold tau | Prevent sidecar-only noise from moving classes the anchor considers implausible. |
| OOF class gate | Open only classes where offline sidecar replay helped the anchor. |
Movement budget D | Limit mean absolute rank movement from the anchor. |
| Top-3 / top-10 overlap | Reject corrections that reorder too much of the head of the prediction. |
| Schema validation | Ensure row order, class columns, finite values, and [0, 1] bounds. |
The perturbation budget is:
\[D = \operatorname{mean}\left(\left|B - A\right|\right)\]For the PCEN sidecar in this run:
| Knob | Value |
|---|---|
SIDECAR_EXP002_VARIANT | exp002b_5s |
SIDECAR_EXP002_FOLDS | [0] |
SIDECAR_EXP002_WEIGHT_CAP | 0.030 |
SIDECAR_EXP002_D_BUDGET | 0.004 |
SIDECAR_EXP002_ANCHOR_TOPK | 48 |
SIDECAR_EXP002_SIDE_TOPK | 32 |
SIDECAR_EXP002_TAU | 0.55 |
SIDECAR_EXP002_GATE_CSV | exp002b_oof_gate.csv |
SIDECAR_EXP002_USE_OOF_GATE | True |
The gate CSV is produced outside the notebook from replay/OOF artifacts. Conceptually, for each class (c), it asks:
\[\Delta_c(w) = \operatorname{AUC}_c\left(A + wM(S-A)\right) - \operatorname{AUC}_c(A)\]Then the sidecar opens class (c) only if the best masked blend gives reliable positive delta after shrinkage checks. Classes that do not pass remain exactly anchored because their gate_weight is zero.
Show notebook snippet: loading PCEN OOF gate weights
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
def _load_exp002_gate_weights(asset_root, class_cols):
if not SIDECAR_EXP002_USE_OOF_GATE:
return None
gate_path = Path(asset_root) / str(SIDECAR_EXP002_GATE_CSV)
if not gate_path.exists():
if SIDECAR_EXP002_GATE_REQUIRE_FILE:
raise FileNotFoundError(f"{SIDECAR_EXP002_LABEL} OOF gate CSV not found")
return None
gate = pd.read_csv(gate_path)
assert "primary_label" in gate.columns
assert "gate_weight" in gate.columns
assert gate["primary_label"].is_unique
weight_map = dict(zip(gate["primary_label"], gate["gate_weight"]))
weights = np.array(
[float(weight_map.get(str(col), 0.0)) for col in class_cols],
dtype=np.float32,
)
weights = np.clip(weights, 0.0, float(SIDECAR_EXP002_GATE_MAX_WEIGHT))
assert np.isfinite(weights).all()
enabled_count = int((weights > 0).sum())
if SIDECAR_EXP002_REQUIRE and enabled_count == 0:
raise ValueError(f"{SIDECAR_EXP002_LABEL} OOF gate has zero enabled classes")
return weights
5. PCEN/ConvNeXt Correction Logic
The PCEN sidecar is a custom log-mel / PCEN ConvNeXt path. The active variant is exp002b_5s, which expects:
| Asset Field | Value |
|---|---|
| context seconds | 5.0 |
| target seconds | 5.0 |
| image time | 256 |
| timeout | 600 seconds |
| requested folds | [0] |
PCEN is useful because it emphasizes different signal properties than the anchor branches. Where the anchor leans heavily on Perch, ProtoSSM, distilled SED, prior correction, and rank scaling, the PCEN sidecar can contribute local evidence for acoustic patterns that the anchor under-ranks.
But it is also riskier. For that reason, it is not added as:
1
p_final = 0.97 * p_anchor + 0.03 * p_pcen
Instead, it is applied as a masked rank correction:
Show notebook snippet: PCEN masked rank blend
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
def _exp002_masked_rank_blend(anchor_df, side_df, class_weights=None):
assert anchor_df.index.equals(side_df.index)
assert anchor_df.columns.equals(side_df.columns)
A = _exp002_rank_cols(anchor_df).to_numpy(np.float32)
S = _exp002_rank_cols(side_df).to_numpy(np.float32)
mask = _exp002_topk_mask(A, SIDECAR_EXP002_ANCHOR_TOPK) | (
_exp002_topk_mask(S, SIDECAR_EXP002_SIDE_TOPK)
& (A >= float(SIDECAR_EXP002_TAU))
)
if class_weights is None:
E = float(np.mean(mask * np.abs(S - A)))
w_budget = 0.0 if E <= 1e-12 else float(SIDECAR_EXP002_D_BUDGET) / E
w = min(float(SIDECAR_EXP002_WEIGHT_CAP), w_budget)
B = A.copy()
if mask.any() and w > 0:
B[mask] = A[mask] + w * (S[mask] - A[mask])
else:
W = np.clip(class_weights, 0.0, float(SIDECAR_EXP002_GATE_MAX_WEIGHT))
WW = np.broadcast_to(W[None, :], A.shape)
B0 = A.copy()
if mask.any() and W.max() > 0:
B0[mask] = A[mask] + WW[mask] * (S[mask] - A[mask])
D0 = float(np.mean(np.abs(B0 - A)))
if D0 > float(SIDECAR_EXP002_D_BUDGET) and D0 > 1e-12:
W = W * (float(SIDECAR_EXP002_D_BUDGET) / D0)
WW = np.broadcast_to(W[None, :], A.shape)
B = A.copy()
if mask.any() and W.max() > 0:
B[mask] = A[mask] + WW[mask] * (S[mask] - A[mask])
D = float(np.mean(np.abs(B - A)))
top3 = _exp002_topk_overlap(A, B, 3)
top10 = _exp002_topk_overlap(A, B, 10)
ok = (
D > 0.0
and active <= float(SIDECAR_EXP002_MAX_ACTIVE_FRACTION)
and top3 >= float(SIDECAR_EXP002_MIN_TOP3_OVERLAP)
and top10 >= float(SIDECAR_EXP002_MIN_TOP10_OVERLAP)
)
This code encodes a useful competition principle:
A specialized side model should earn the right to move the anchor class by class.
Global blending assumes the sidecar is broadly calibrated. OOF-gated masked rank correction assumes something weaker and often more realistic: the sidecar may be good for some classes and harmful for others.
6. BirdNET Sidecar
BirdNET is handled with the same caution. It is not allowed to move every label. The notebook distinguishes:
| Group | Weight Cap |
|---|---|
| covered Aves classes already mapped by Perch | 0.015 |
| covered Aves classes where Perch is weaker or unmapped | 0.060 |
| non-bird classes | 0.000 |
The intended effect is:
1
2
3
use BirdNET where it has direct biological/audio coverage,
give it a larger voice where the anchor has weaker direct mapping,
keep non-bird taxa anchored.
The dry-run output explains why this branch did not change the public notebook preview:
1
2
BirdNET row_id mismatch; keeping anchor submission. missing=3, extra=12
BirdNET sidecar elapsed: 2.1s
That fallback is intentional. If the sidecar cannot align to the canonical submission rows, it must not write a partially mismatched correction.
7. Public Dry-Run Behavior
The notebook output shown in the public environment is a dry run because the hidden test soundscapes are not mounted. That creates two important effects:
| Stage | Dry-Run Result |
|---|---|
| yukiZ branch | runs on dry-run rows and aligns to sample_submission.csv |
| PowerOptimization PSSM branch | writes diagnostic and intermediate CSVs |
| PowerOptimization EoS9 branch | writes the dominant anchor CSV |
| taxonomy smoothing | applies successfully using taxonomy.csv |
| BirdNET sidecar | skipped because row IDs do not match anchor rows |
| PCEN sidecar | skipped because test_soundscapes/*.ogg files are not visible |
| final output | remains the taxonomy-smoothed anchor |
The notebook reports:
1
2
3
4
Wrote submission.csv: rows=3, cols=235, min=0.461531, max=0.529922
final_D_vs_base_anchor: 0.0
final_top3_overlap_vs_base: 1.0
final_top10_overlap_vs_base: 1.0
Zero movement in this preview should not be interpreted as evidence that the sidecars have no hidden-test effect. It means the public dry run did not have matching soundscape inputs for those sidecar corrections. In a real test run, the sidecar path is allowed to execute only if its assets, row IDs, class columns, OOF gates, and movement diagnostics all pass.
8. Final Writer And Submission Safety
The final writer is one of the most important parts of the notebook. High-scoring Kaggle notebooks often fail not because the model is weak, but because the final submission.csv has a silent schema problem:
| Failure | Example |
|---|---|
| row mismatch | sidecar emits different row_id set |
| column mismatch | model class order differs from sample_submission.csv |
| duplicate rows | repeated row_id after merge |
| invalid values | NaN, inf, or values outside [0, 1] |
| index leakage | accidental Unnamed: 0 column |
This notebook reloads and checks the file after writing.
Show notebook snippet: final submission writer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
def _align_to_sample_submission_if_possible(df):
sample_path = _find_sample_submission_path()
if sample_path is None:
return df
sample = pd.read_csv(sample_path)
assert "row_id" in sample.columns
assert sample["row_id"].is_unique
sample_cols = sample.columns.tolist()
missing_cols = [c for c in sample_cols if c not in df.columns]
assert not missing_cols
final_ids = set(df["row_id"])
sample_ids = set(sample["row_id"])
if final_ids == sample_ids:
aligned = (
df.set_index("row_id")
.loc[sample["row_id"], sample_cols[1:]]
.reset_index()
)
aligned.columns = sample_cols
return aligned
raise AssertionError("final row_id set differs from sample_submission")
def write_final_submission(pred, path="submission.csv"):
df = _as_explicit_submission_table(pred)
df = _align_to_sample_submission_if_possible(df)
prob_cols = [c for c in df.columns if c != "row_id"]
values = df[prob_cols].to_numpy(dtype=np.float32)
assert np.isfinite(values).all()
assert values.min() >= 0.0 and values.max() <= 1.0
df.to_csv(path, index=False)
check = pd.read_csv(path)
assert check.columns.tolist() == df.columns.tolist()
assert len(check) == len(df)
assert check["row_id"].is_unique
return df
This is more than defensive programming. It is what makes sidecar experimentation safe. If BirdNET, PCEN, taxonomy smoothing, or any branch alignment creates a schema mismatch, the notebook either keeps the anchor or fails loudly.
9. How To Read The Notebook Outputs
The most useful output blocks are not the giant inference logs. They are the compact summaries:
| Output | Interpretation |
|---|---|
| Active model list | Confirms which anchor branches are contributing. |
| Weight table | Confirms the outer blend sums to one. |
| Sidecar overview | Confirms whether BirdNET and PCEN are active and which gates/budgets they use. |
| Taxonomy smoothing printout | Confirms taxonomy.csv, genus groups, class groups, and alpha values. |
| Branch diagnostics | Confirms row count, class count, min/max probability, and duplicate rows. |
| Final preview | Shows the actual submission.csv after all enabled corrections. |
| Final delta summary | Confirms how far final ranks moved from the pre-sidecar anchor. |
For this public dry run, the main diagnostic story is:
1
Anchor branches run -> taxonomy smoothing applies -> sidecars cannot match dry-run inputs -> final remains anchor.
That fallback is the desired behavior. The public notebook remains reproducible, while the hidden-test path is ready to apply sidecars when real test soundscapes are present.
10. Why This Structure Is Useful
The strongest idea in the notebook is not any single threshold. It is the separation of responsibilities:
| Responsibility | Implementation Pattern |
|---|---|
| preserve known public strength | keep EoS9 as the anchor |
| add biological prior | taxonomy smoothing after direct blend |
| test new models safely | sidecars as masked corrections, not global blends |
| avoid over-moving ranks | D budgets and top-k overlap checks |
| use offline evidence | class-wise OOF gate weights |
| protect submission format | final writer with schema and range checks |
This structure also makes experiments interpretable. If the PCEN sidecar improves score, the improvement is not mixed with a changed anchor. If it hurts, the diagnostics can show whether the harm came from too many active cells, too much rank movement, weak OOF gates, or bad row alignment.
The notebook therefore functions less as a single model recipe and more as a small experiment framework:
1
2
3
4
fixed anchor
+ controlled taxonomy prior
+ optional class-gated sidecar movement
+ strict final validation
11. References
| Reference | Used In This Notebook As |
|---|---|
| F.A.Nina, birdclef-2026-eos-9 | primary EoS9 anchor structure |
| Karnakbayev Artur, power-optimization | PowerOptimization branch and validation style |
| yukiZ, Perch + ProtoSSM + ResSSM | low-weight pretrained diversity branch |
| Tucker Arrants, BC2026 Distilled SED | distilled SED ONNX branch |
custom exp002 / exp002b assets | optional PCEN/log-mel ConvNeXt sidecars |
12. What This Notebook Establishes
This notebook establishes a disciplined way to extend a strong public BirdCLEF anchor:
- Build the submission around a known strong EoS9-style control path.
- Apply taxonomy smoothing as a small, interpretable biological prior.
- Treat side models as local rank corrections, not unconditional ensemble members.
- Use OOF gates so sidecars move only classes where offline evidence supports them.
- Enforce row, column, finite-value, range, and duplicate checks at the final writer.
The result is a submission architecture that is flexible but controlled. It can attach PCEN/ConvNeXt and BirdNET side evidence, while still requiring every sidecar movement to pass a mask, a class gate, and a perturbation budget.
That is the central lesson:
In a high-dimensional multilabel audio competition, the safest way to add a new model is not to blend it everywhere. It is to let it move only where it has earned trust.